[Paper Review] Deep Neural Networks for YouTube Recommendations
Source
Summary
Contents
0. Abstract
유튜브는 현재 존재하는 가장 대규모이면서 정교한 산업용 추천 시스템 중 하나이다. 이 논문에서는 유튜브 추천 시스템을 전체적인 관점에서 설명하며, 딥러닝이 가져온 극적인 성능 향상에 초점을 맞춘다. 이 논문은 전통적인 2단계 정보 검색 구조를 기준으로 나뉜다. 먼저, ⅰ) 딥러닝 기반 후보군 생성 모델(Deep Candidate Generation Model) 을 자세히 설명하고, ⅱ) 딥러닝 기반 순위 결정 모델(Deep Ranking Model)을 소개한다. 또한, 대규모 추천 시스템을 설계하고, 반복적으로 개선하며, 운영하는 과정에서 얻은 실질적인 교훈과 통찰을 공유한다. 이 시스템은 방대한 사용자에게 직접적인 영향을 미친다.
1. Introduction
Problem
유튜브는 비디오 콘텐츠를 제작, 공유, 발견하는 세계에서 가장 큰 플랫폼이다. 유튜브 추천 시스템은 10억 명 이상의 사용자가 지속적으로 증가하는 방대한 동영상 모음(corpus)에서 개인화된 콘텐츠를 발견할 수 있도록 돕는다. 이 논문에서는 딥러닝이 최근 유튜브 추천 시스템에 미친 엄청난 영향에 초점을 맞춘다. 유튜브 비디오 추천은 다음 세 가지 주요 관점에서 매우 어려운 과제를 안고 있다.
ⅰ) Scale 문제
기존의 추천 알고리즘 중에서 소규모 문제에서는 성능이 우수한 알고리즘도 유튜브 규모에서는 제대로 작동하지 않는다. 유튜브의 거대한 사용자 기반과 방대한 데이터(corpus)를 처리하려면, 고도로 특화된 분산 학습 알고리즘과 효율적인 시스템이 필수적이다.ⅱ) Freshness문제
유튜브는 매초마다 수많은 시간이 넘는 동영상이 업로드되는 매우 동적인 콘텐츠 저장소이다. 추천 시스템은 새로 업로드된 콘텐츠뿐만 아니라 사용자가 최근에 수행한 행동도 신속하게 반영할 수 있어야 한다. 새로운 콘텐츠와 기존의 인기 동영상 간의 균형을 맞추는 문제는 탐색/활용관점에서 이해할 수 있다.ⅲ) Noise문제
유튜브에서 사용자의 과거 행동을 예측하는 것은 본질적으로 어렵다. 그 이유는 데이터의 희소성과 관찰할 수 없는 수많은 외부 요인 때문이다. 우리는 사용자의 만족도에 대한 Ground Truth을 거의 얻을 수 없다. 대신, 노이즈가 포함된 암묵적 피드백 신호를 모델링해야 한다. 게다가, 콘텐츠에 관련된 metadata는 명확한 ontology(개념 체계) 없이 구조화가 잘 되어 있지 않다. 우리의 알고리즘은 이러한 훈련 데이터의 특정한 특성에 대해 강인해야 한다.
구글의 다른 제품 영역과 함께, 유튜브는 대부분의 학습 문제를 해결하기 위한 범용 솔루션으로 딥러닝을 활용하는 근본적인 패러다임 전환을 경험하고 있다. 우리의 시스템은 Google Brain 프로젝트를 기반으로 구축되었으며, 이 프로젝트는 최근 오픈 소스로 공개되어 TensorFlow로 출시되었다. TensorFlow는 대규모 분산 학습을 활용하여 다양한 deep neural network architecture를 실험할 수 있는 유연한 프레임워크를 제공한다. 우리의 모델은 약 10억 개의 parameter를 학습하며, 수천억 개의 example을 사용하여 훈련된다.
Previous work
행렬 분해(Matrix Factorization) 기반 추천 시스템에 대한 연구는 많지만, deep neural network를 활용한 추천 시스템 연구는 상대적으로 적다. deep neural network는 뉴스 추천, 논문 인용 추천, 리뷰 평점 예측 등에 사용되었다. 또한, 협업 필터링(Collaborative Filtering)은 deep neural network 및 오토인코더(Autoencoder)를 활용하여 모델링되었다.
이 논문의 구성은 다음과 같다. Section 2에서는 시스템 개요를 간략히 설명한다.
Section 3에서는 후보군 생성 모델(candidate generation model) 을 자세히 설명하며, 이 모델의 훈련 과정과 추천 서비스에서의 활용 방식을 다룬다.
Section 4에서는 순위 결정 모델(ranking model)을 상세히 설명하며, 기존의 logistic regression를 수정하여 click probability이 아니라, expected watch time을 예측하는 방식을 다룬다.
마지막으로, Section 5에서는 결론과 연구 과정에서 얻은 교훈을 제시한다.
2. Sysyem Overview
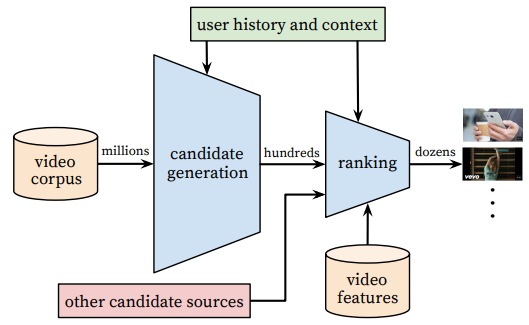
우리의 추천 시스템의 전체 구조는 위와 같다. 이 시스템은 두 개의 신경망으로 구성되어 있다. 하나는 후보군 생성(candidate generation)을 위한 것이고, 다른 하나는 순위 결정(ranking) 을 위한 것이다.
Candidate Generation Network
후보군 생성 네트워크는 사용자의 유튜브 활동 기록을 입력으로 받아들여, 대규모 동영상 데이터(corpus)에서 수백 개의 동영상(subset)을 추출한다. 이렇게 선택된 후보군은 사용자와의 높은 연관성을 가지도록 설계된다. 후보군 생성 네트워크는 협업 필터링을 사용해, 넓은 범위에서 개인화를 수행한다. 사용자 간의 유사성은 다음과 같은 단순한(coarse) 특징(features)을 기반으로 계산된다.
- 사용자가 시청한 동영상의 ID
- 검색어
- 사용자의 인구통계 정보
Ranking
최종적으로 사용자에게 최적의 추천을 제공하려면, 후보군 내에서 상대적인 중요도를 구별할 수 있는 세밀한 표현이 필요하다. 순위 결정 네트워크는 사용자와 동영상을 설명하는 다양한 특징을 활용하여, objective function에 따라 각 동영상에 점수를 부여하는 방식으로 이 작업을 수행한다. 가장 높은 점수를 받은 동영상이 최종적으로 사용자에게 추천되며, 점수에 따라 순위가 결정된다.
System
이 두 단계 추천 시스템 덕분에, 우리는 수백만 개의 동영상 중에서 효과적으로 추천을 수행할 수 있으며, 최종적으로 사용자에게 표시되는 소수의 동영상이 개인화되고, 몰입도를 높일 수 있도록 보장할 수 있다. 게다가 이러한 design은 이전에 제안된 방식과 같이, 다른 source에서 생성된 후보군과도 합쳐질 수 있다.
개발 과정에서 우리는 정확도(precision), 재현율(recall), 랭킹 손실(ranking loss) 등 오프라인 평가 지표를 활용해 반복적인 개선을 수행한다. 그러나 알고리즘이나 모델의 최종적인 효과는 실제 A/B 테스트(live experiments)를 통해 평가한다. 실제 live 실험에서 우리는 클릭률(CTR, Click-Through Rate), 시청 시간(Watch Time), 그리고 사용자 참여도를 측정하는 다양한 지표에서의 미묘한 변화를 측정할 수 있었다. 이것이 중요한 이유는, 실제 A/B 테스트 결과가 오프라인 실험 결과와 항상 일치하는 것은 아니기 때문이다.
3. Candidate Generation
후보군 생성과정에서, 거대한 유튜브 동영상 데이터(corpus) 중 사용자와 관련이 있을 가능성이 있는 수백 개의 동영상으로 범위를 좁힌다. 여기에서 설명하는 추천 시스템의 이전 버전은, rank loss를 기반으로 학습된 행렬 분해 기법을 사용했다. 우리 network의 초기 interation에서는 , 얕은 신경망을 사용하여 행렬 분해의 동작 방식을 모방했으며, 사용자의 이전 시청 기록만을 임베딩하는 방식이었다. 이러한 관점에서 보면, 우리의 접근 방식은 행렬 분해 기법의 비선형적 일반화로 볼 수 있다.
3.1 Recommendation as Classification
우리는 추천 문제를 극단적인 multiclass classification 문제로 접근한다. 즉, 사용자 $U$와 컨텍스트 $C$를 기반으로, 특정 시점 $t$에서 사용자가 시청할 특정 동영상 $w_t$를, 수백만 개의 동영상 V(클래스) 중에서 class $i$를 정확하게 분류하는 문제로 정의한다.
\[P(w_t = i \vert U, C) = \frac{e^{v_iu}}{\sum_{j \in V} e^{v_j u}}\]여기서 $u \in \mathbb{R}^N$는 사용자와 context에 대한 고차원의 embedding을 나타내고, $v_j \in \mathbb{R}^N$은 각 candidate video의 embedding을 나타낸다. 이 setting에서, embedding은 단순히 sparse entities(개별 동영상, 사용자 등)를 고차원 벡터 공간 $\mathbb{R}^N$에 매핑하는 과정을 의미한다. 딥 뉴럴 네트워크의 역할은 사용자의 시청 기록과 컨텍스트를 반영하여, 사용자 embedding $u$를 학습하는 것이다. 이렇게 학습된 임베딩은 softmax classifier를 통해 동영상 간 차이를 효과적으로 구별하는 데 활용된다.
유튜브에는 explicit feedback mechanisms(좋아요/싫어요, 사용자 설문 등)이 존재하지만, 우리는 사용자의 implicit feedback(시청 기록)을 활용하여 모델을 학습한다. 예를 들어, 사용자가 영상을 끝까지 시청하면 이를 positive example로 간주한다. 이러한 선택(implicit feedback)은 훨씬 더 방대한 규모의 implicit user history를 이용할 수 있기 때문이다. 이를 통해 explicit feedback이 거의 없는 “롱테일(long-tail)” 영역에서도 추천을 생성할 수 있다.
수백만 개의 클래스를 가진 모델을 효율적으로 학습하기 위해, 우리는 candidate sampling기법을 활용하여 negative classes를 배경 분포에서 선택하고, 이를 importance weighting를 통해 보정하는 방식을 사용한다. 각 학습 예제마다, 실제 정답과 샘플링된 negative classes에 대해 cross-entropy loss를 최소화한다. 실제로, 수천 개의 negative samples를 샘플링하며, 이를 통해 전통적인 Softmax 대비 100배 이상의 속도 향상을 달성할 수 있다. hierarchical softmax는 널리 사용되는 대안적인 접근 방식이지만, 우리 실험에서는 비슷한 수준의 정확도를 달성하지 못했다. hierarchical softmax에서는, 트리의 각 노드를 탐색할 때 서로 관련이 없는 클래스 집합 간의 구분이 필요하다. 이로 인해 분류 문제가 더욱 어려워지고, 성능이 저하되었다.
실제 서비스 단계에서는 가장 높은 확률을 가진 N개의 동영상(N classes)을 계산하여, 사용자에게 추천할 최상위 N개를 선택해야 한다. 수백만 개의 동영상을 평가하는 과정은, 수십 밀리초 내의 엄격한 Serving Latency 제한을 만족해야 한다. 이를 위해, 클래스 개수(=동영상 수)에 대해 sublinear 연산 속도를 갖는 approximate scoring scheme이 필요하다. 과거 유튜브 시스템에서는 Hashing 기법을 활용했으며, 여기에서 설명하는 classifier도 유사한 접근 방식을 사용한다. 실제 추천 서비스 단계에서는, Softmax 출력층에서의 likelihoods을 정확하게 조정할 필요가 없다. 따라서, 이 문제는 “내적(dot product) 공간에서의 Nearest Neighbor Search” 문제로 변환할 수 있으며, 이를 위해 범용 라이브러리를 사용할 수 있다. 우리는 A/B 테스트 결과, 최근접 이웃 검색(Nearest Neighbor Search) 알고리즘의 선택이 추천 품질에 큰 영향을 미치지 않음을 확인했다.
3.2 Model Architecture
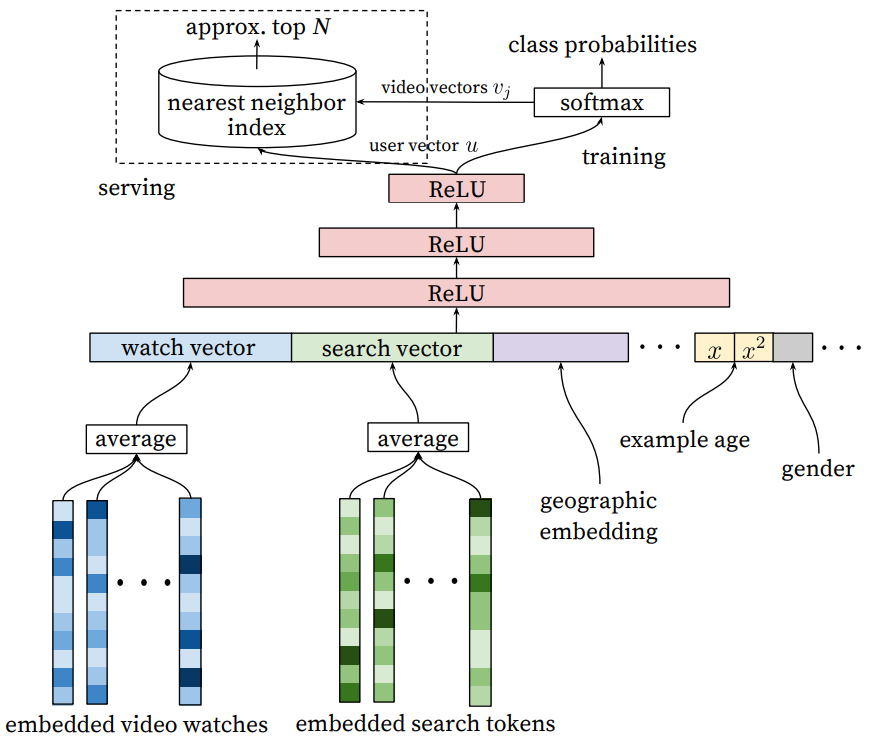
우리는 연속적 Bag of Words 언어 모델에서 영감을 받아, 고차원 비디오 임베딩(Embeddings)을 학습하며, 이 임베딩을 Feedforward Neural Network에 입력한다. 사용자의 시청 기록은 가변 길이의 Sparse한 비디오 ID 시퀀스로 표현되며, 이 시퀀스는 임베딩을 통해 Dense 벡터 표현으로 변환된다. 신경망은 고정된 크기의 Dense한 입력을 필요로 하며, 임베딩을 단순히 Averaging하는 방법이 다른 방법들(합산, 요소별 최대값 등)보다 가장 좋은 성능을 보였다.