[Paper Review] Vision Transformers Need Registers
Source
Contents
0. Abstract
이 논문에서는 Self-Supervised Learning과 Supervised Learning을 ViT와 함께 사용할 때 Feature Map에서 나타나는 “artifact”라는 것을 정의하고 분석할 것이다. 이 “artifact”는 주로 이미지의 배경같은 정보량이 적은 영역에서 특정 토큰에 높은 값을 할당하는 현상으로 계산 과정에서 문제를 일으킬 수 있다. 우리는 이를 해결하기 위해 입력 시퀀스에 추가 토큰을 제공하여 이러한 역할을 대체하는 간단하면서도 효과적인 해결책을 제안한다. 이러한 방법은 Supervised Learning과 Self-Supervised Learning 모델 모두에서 위의 문제를 완전히 해결였고, Self-Supervised Learning의 Dense Prediction성능을 올렸으며 Down Stream Task의 Attention map을 더 smooth하게 만들어 주었다.
1. Introduction
Background
이미지를 다양한 목적으로 사용할 수 있는 Generic Feature로 Embedding하는 것은 오래된 문제이다. 초기에는 SIFT와 같은 Handcraft 규칙에 의존했지만, Data와 Deeplearning기술이 발전하면서 End-to-End 학습으로 수행한다. 이 과정에서 유용한 Annotated Data가 더 중요해진 만큼 Generic Feature를 만드는 것도 더욱 중요해 졌고, 오늘날에는 특정 모델을 Pretrain함으로써 이러한 Generic Feature를 얻고 있다. 한편 Transformer를 기반으로한 Self-Supervised Learning은 Downstream task에서 뛰어난 성능을 보여 주목을 받고 있다.
Previous Work (DINO, LOST)
특히 DINO 알고리즘은 Image의 Semantic정보를 잘 학습하는 것으로 알려졌는데, 실제로 정성적 결과를 보면 Attention Layer가 자연스럽게 이미지에서 Semantically Consistent한 부분에 초점을 맞추며 해석 가능한 Attention Map을 생성함을 알 수 있다. 이러한 속성을 활용하여 LOST와 같은 알고리즘은 Supervision없이 Attention map의 정보를 활용해 물체를 탐지할 수 있다.
Problem
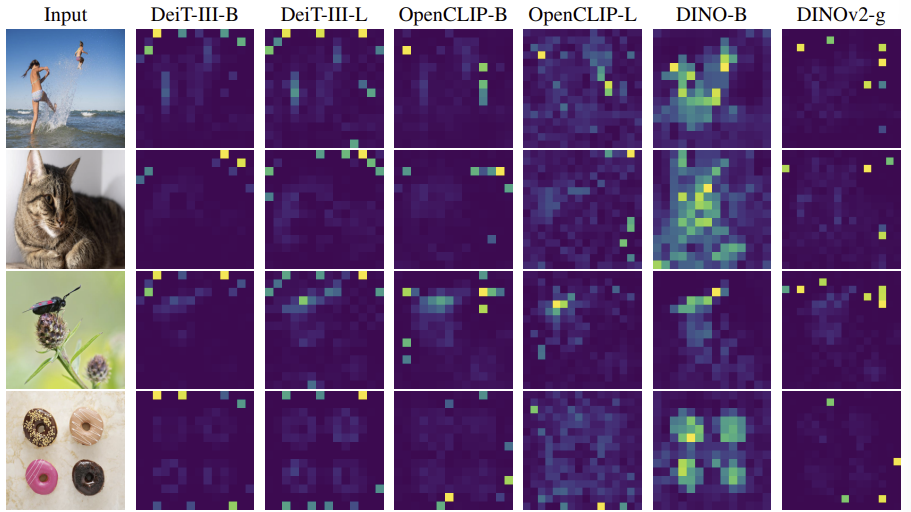
DINO의 후속 모델인 DINOv2는 Frozen Backbone과 Linear Model만으로도 Dense Prediction에서 성공적인 결과를 이끌었다. 하지만 DINOv2는 LOST와는 놀라울 정도로 호환이 되지 않는 것으로 관찰되었다. 이는 DINOv2가 DINO와는 다르게 동작한다는 것을 시사하고, 이 연구에서는 DINOv2의 Featuremap에 DINO에서는 존재하지 않았던 Artifact가 있음이 밝혀냈다. 또한 Supervised Vision Transformer에서도 유사한 Artifact가 나타나는 것을 발견했는데, 즉 DINO가 예외적인 모델이었다는 것을 알 수 있었다.
Analysis
이 연구에서는 이 현상을 잘 이해하고 Artifact를 감지할 방법을 개발하고자 한다. 우선 이러한 Artifact의 특징은 다음과 같다.
- 다른 Token들보다 10배 큰 값을 갖고 있다.
- 전체 Sequence에서 약 2%에 해당하는 작은 부분에서 발견된다.
- Vision Transformer의 중간 Layer에서 발생한다.
- 매우 큰 모델을 오래 학습한 경우에만 발생한다.
- 이웃한 Patch와 유사한 값을 갖는 Patch, 즉 배경처럼 중복된 정보가 많거나 정보가 부족한 부분에서 발생한다.
이러한 Outlier Token들은 Non-Outlier Token에 비해 이미지에서 원래 위치나 Pixel정보를 덜 포함하고 있다는 것을 관찰했다. 즉, 모델이 추론중에 이러한 Patch에 포함된 Local한 정보를 없앤다는 것을 알 수 있다. 반면에 이 Outlier Patch에서 이미지를 분류하는 모델을 학습하면 꽤 높은 정확도를 보이는데, 이는 Outlier Patch에는 Global한 정보를 많이 포함하고 있다는 것을 알 수 있다.
즉, 이를 통해 모델은 유용한 정보가 거의 없는 패치를 인식하고 해당 Token을 재활용해서 Global Information을 모으고 Local Information을 폐기한다는 것을 알 수 있다.
Solution
위의 해석은 [CLS]토큰으로 Global한 정보를 모아 계산하는 Transformer 모델의 내부 메커니즘과 일치한다. 이 가설을 검증하기 위해 Image와 독립적인 추가적인 Token, 즉 Register를 입력 Token Sequence와 함께 넣은 결과 이러한 Outlier가 Sequence에서 완전히 사라지는 것을 관찰했다. 그 결과 모델의 Dense Prediction 성능이 향상되었고, 또한 생성된 Featuremap도 훨씬 매끄러워진 것을 알 수 있었다.
2. Problem Formulation
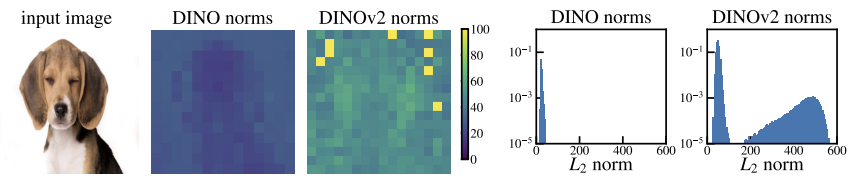
정의: Artifacts are high-norm outlier tokens
(DINO: ViT-B/16, DINOv2: ViT-g/14)
우리는 Artifact에 대한 정량적인 특징을 찾고 싶었고, 실험 결과 Token embedding의 norm에서 다른 patch들과 차이가 있다는 것을 발견했다. 위의 그림을 보면 알 수 있듯이 이미지에서 매우 적은 부분에서 high-norm을 갖는 Token이 있는 것을 알 수 있다.
(※ DINOv2에서 Bimodal이 발생하는 기준인 150을 high norm의 기준으로 설정하였다. 이때, 2.37%의 token만이 high norm으로 판별되었다.)
(※ Artifact == High norm token)
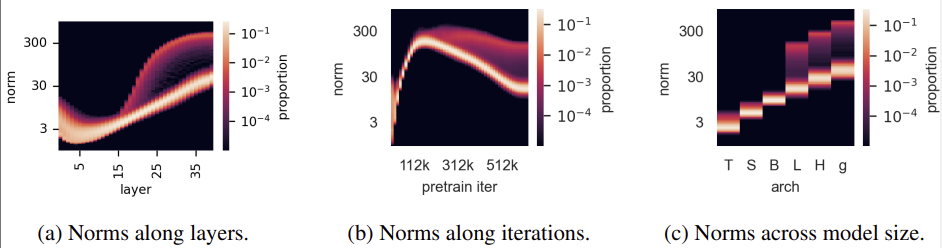
특징1(발생조건): Outliers appear during the training of large models
(DINOv2: ViT-g/14, 40Layer)
우리는 artifact가 발생하기 위한 조건들을 발견했다.
(※ 위에서 Bimodal이 발생하는 부분을 찾으면 될 것 같다.)
- (a) 40 Layer중에서 15번째 Layer부터 Outlier가 발생하기 시작한다.
- (b) 전체 Training iteration중에서 $\frac{1}{3}$에서 Outlier가 발생하기 시작한다.
- (c) ViT-Large보다 더 클 경우에만 Outlier가 발생한다.
특징2(발생위치): High-norm tokens appear where patch information is redundant
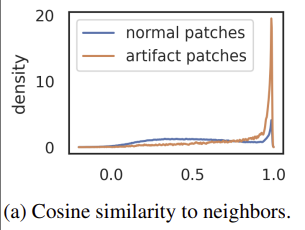
Patch embedding Layer(ViT의 첫번째 Layer)에서 각 Token들에 대해 이웃한 4방향의 Token들과 Cosine Similarity를 비교하였다. 그 결과 High-norm token(Artifact Patch)들은 주변 Token들과 유사했다는 것을 알 수 있는데, 이는 앞서 정의 부분에서 보았던 그림의 정성적 비교(Background에 Artifact 존재)와도 일치한다.
특징3(지역정보): High-norm tokens hold little local information
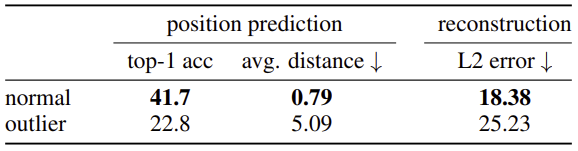
Patch embedding위에 Linear model을 올리고 이 모델의 Position Prediction과 Pixel Reconstruction에 대한 성능을 비교해 보았다.
- Position Prediction
- Patch embedding은 Position embedding에 의해 위치 정보를 포함하고 있다. 이러한 점에 주목해서 원래 위치를 Prediction하도록 해 보았는데 Artifact가 존재했던 Patch는 원래 위치에 대한 예측 성능이 떨어지는 것을 볼 수 있다.
- Pixel Reconstruction
- 마찬가지로 Patch embedding이 원래 이미지에서의 Pixel값을 예측하도록 한 결과 Artifact가 존재했던 Token에서는 예측 성능이 떨어지는 것을 알 수 있다.
특징4(전역정보): Artifacts hold global information

Global information을 포함하고 있는지에 대한 평가를 위해 Dataset에 대한 Classification 실험결과를 보면 알 수 있듯이 high norm token은 매우 높은 정확도를 가지고 있는 것을 확인할 수 있다. 즉, Outlier token들은 다른 Patch token들보다 Global information을 더 포함하고 있는 것을 알 수 있다.
가설
위의 관찰을 바탕으로 다음과 같은 가설을 새울 수 있다.
- 충분히 큰 모델이 충분히 학습되면, 중복된 토큰을 인식하고 이 토큰들을 Global information을 저장하고 처리 및 검색하는 장소로 사용한다.
우리는 이러한 행동 자체는 나쁘지 않지만, 이것이 Patch token내부에서 발생한다는 사실은 바람직하지 않다고 생각한다. 이로 인해 모델이 Patch의 local information을 버리게 만들고, Dense Prediction task의 성능 저하를 초래할 수 있기 때문이다.
따라서 우리는 이 문제에 대해 새로운 토큰을 Sequence에 추가하여 모델이 Register로써 사용할 수 있도록 하는 해결책을 제시한다.
이는 [CLS] 토큰과 유사하고 Learnable한 값을 가진다. 이 토큰은 Transformer의 마지막에서 버려지고(사용하지 않고) [CLS]토큰과 Patch토큰들은 기존과 같이 Representation으로써 사용된다. 우리는 이 메커니즘이 Vision Transformer에서 자연스러운 정당성을 가지고, 기존에 존재했던 해석가능성과 성능 문제를 해결한다.
우리는 다양한 모델에서 Artifact가 발생하는 원인이 무엇인지 완전히 알아내지는 못했다. Fig2(Introduction의 Problem부분에 있는 그림)를 보면 OpenCLIP과 DeiT에서는 B와 L크기에서 모두 Outlier가 발생한다. 이 외에도 훈련 시간이 중요한 역할을 한다.
3. Experiments
4. Related Work
Feature Extraction with pretrained models
사전 학습된 모델을 사용해 Visual Feature를 추출하는 것은 AlexNet이후로 오랜 시간동안 검증된 방법이다. 최근에는 ResNet이나 ViT와 같은 현대적인 Architecture를 사용해 이를 개선하였다. 트랜스포머는 다양한 모달리티를 훈련중에 활용할 수 있어 Label supervision이나 Text supervision에서 Backbone으로 널리 사용되고 있고, 강력한 Visual Foundation모델을 제공하며 model의 크기를 늘리고 다양한 Task에 적용할 수 있도록 한다. 이러한 상황에서 지도학습은 label에 의존한다. 이에 대해 대안적인 접근법은 지도학습을 사용하지 않고, 모델이 이미지의 내용을 이해할 수 있도록 설계된 Pretext task를 통해 학습하도록 하는 것이다. 이러한 Self-supervised learning 패러다임은 MAE같이 여러 ViT기반 방법에서 탐구되었다. 이와 다른 접근법으로 Self-Distillation 방법들은 고정된 Backbone을 사용하여 좋은 성능을 보이고 Downstream Task에서 강건함을 제공한다. 본 연구에서는 Self-supervised learning에 초점을 맞추고, 특히 DINOv2를 분석하였다. DINOv2는 benchmark에서 뛰어난 성능을 보였지만 바람직하지 않은 Artifact를 보였는데, 이를 수정한다면 성능을 더 개선할 수 있음을 보여주었다. 이러한 현상은 DINOv2에서만 발생하고 DINO에서는 발생하지 않았기에 더 놀라웠다. 우리는 이러한 수정 기법이 Supervised learning에서도 유효하다는 것을 DeiT와 OpenCLIP을 통해 추가로 보여주었다.
Additional tokens in transformers
Transformer에 특수한 토큰을 추가하는 방식은 BERT를 통해 널리 알려졌다. 그러나 대부분의 방법에서 새로운 토큰을 추가하는 목적은 다음과 같았다.
- 네트워크에 새로운 정보를 제공하기 위해(ex. BERT의 [SEP] Token)
- 입력에 대해 더 많은 계산을 수행하도록 하기 위해(ex. AdaTape의 Tape Token)
- Token에 정보를 모아 모델의 출력으로 사용하기 위해(ex. ViT의 [CLS] Token)
- Generative learning(ex. BERT, BEiT의 [MASK] Token)
- Detection Token(ex. DETR)
- Decoding이전에 Modality로부터 정보를 축적하기 위해(ex. Perceivers)
기존 연구와는 달리 우리가 Sequence에 추가하는 Token은 아무런 정보를 갖고 있지 않고, 출력값도 전혀 사용하지 않는다. 이 토큰들은 단순히 Register로써 모델의 순전파동안 정보를 검색하고 저장하는 용도로 학습된다. Memory Transformer는 단순히 메모리 토큰을 token sequence에 추가하여 번역 성능을 향상시켰다. 후속연구에서는 복잡한 Copy-repeat-reverse라는 복잡한 작업을 다루고, 어떤연구에서는 위의 접근법을 비전 도메인에서의 Finetuning으로 확장했지만 다양한 작업으로 일반화되지는 않았다. 반면에, 우리는 Fine tuning을 사용하지 않고 사전학습 도중에 Additional token을 사용해 Feature를 개선하였다. 또한 더 중요한 부분은 앞서 증명했듯이 Vision Transformer가 memory token을 사용한다는 것을 증명한 부분이다.
Attention maps of vision transformers
[CLS] 토큰의 Attention map을 보여주는 것은 DINO에서 널리 알려졌다. DINO에서는 이전의 Transformer들과는 달리 Attention map이 Artifact없이 깨끗하게 나타나는 것을 보여주었다. 이후 연구에서는 다양한 기법을 사용해 이러한 Attention map을 관찰하였다.