10. Self-Supervised Learning
Self-Supervised with Transformer
1) SiT
(Self-Supervised Vision Transformer)
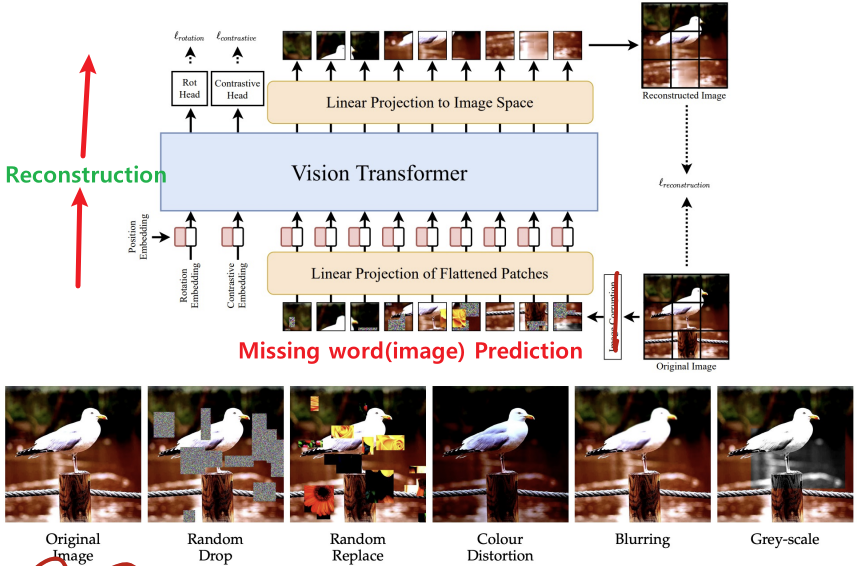
Reconstruction(이미지 복원을 통한 학습)
2) BEIT
(Bert Pre-Training of Image Transformer)
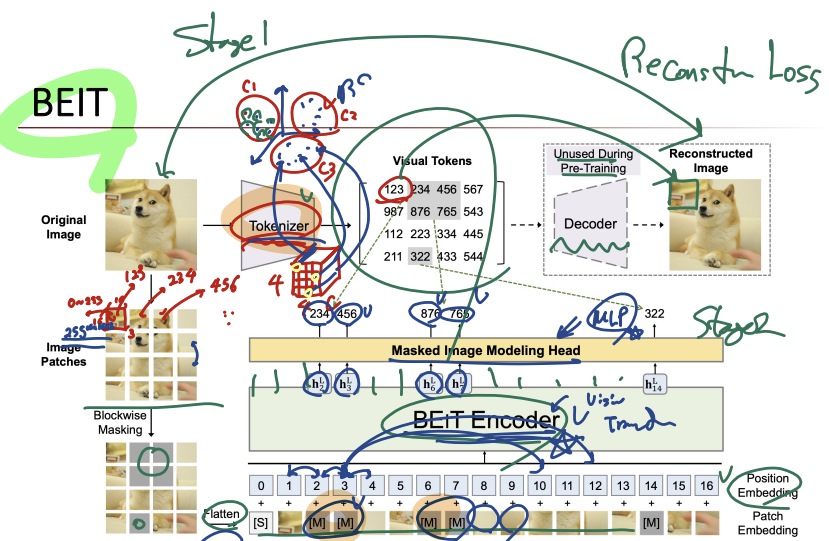
Mask Prediction(마스킹된 토큰을 예측함으로써 학습)
3) MAE
(Masked Autoencoders)
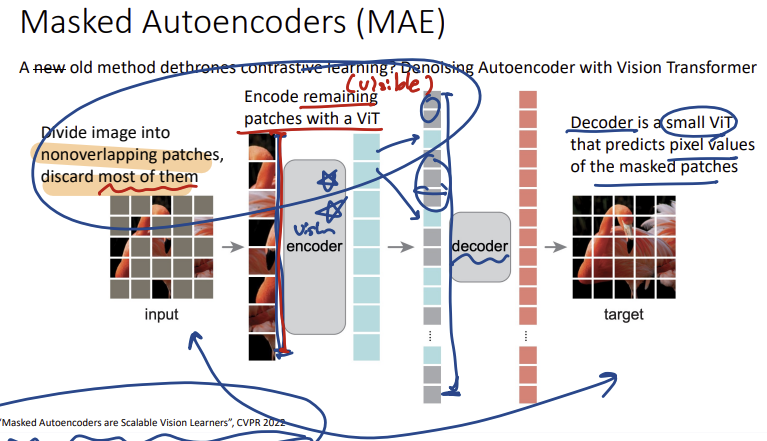
Reconstruction(이미지 복원을 통한 학습)
Multi-modal Self-Supervised Learning
1) VirTex
이미지와 Caption을 같이 학습하는 모델
Caption이 가지는 Sematic Density덕분에 Contrastive Learning이나 Classification Pretraining에 비해 더 효과적임을 증명
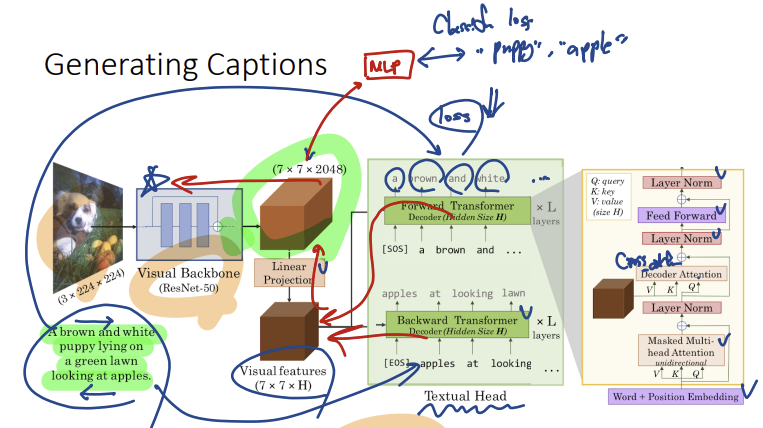
- 이미지 입력 & Feature 변환
Transformer를 사용해 Caption생성
(이 때, 양방향의 Caption을 생성하도록 설계함)- 실제로 Caption이 더 많이질수록 더 좋은 성능을 가지는 것도 확인함
2) CLIP
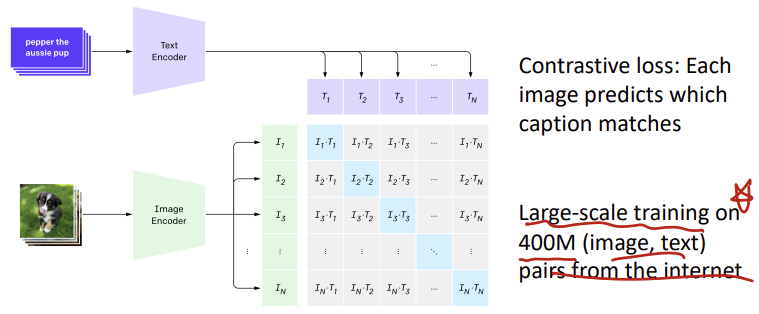
Contrastive Learning과 같이 학습한다.
이미지와 Text에대해 Matching되는 부분은 Positive, 그렇지 않은 부분에 대해서는 Negative Sample로써 동작한다.
-> 매우 많은데이터가 필요하다는 단점
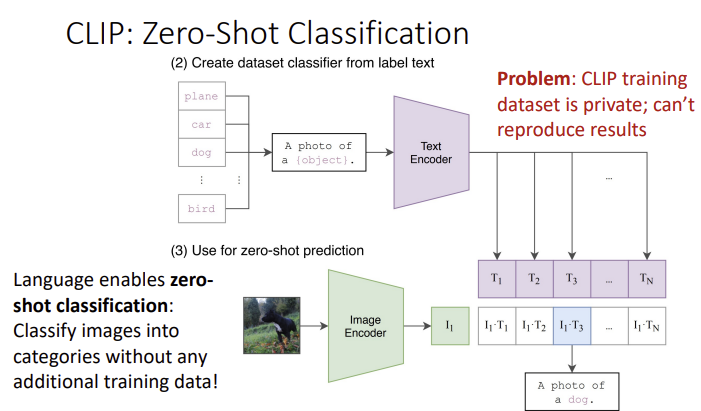
pre-defined word embedding이 필요함
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.