8. Segmentation(Instance, Panoptic)
Segmentation
1. Background
1) Segmentation의 종류
Segmentation의 Task를 구분하는 가장 중요한 “Things”와 “Stuff”이다.
- Things: 일반적으로 볼 수 있는 물체들을 의미한다.
- Stuff: 하늘, 땅, 길, 숲 등과 같은 무정형의 지역을 의미한다.
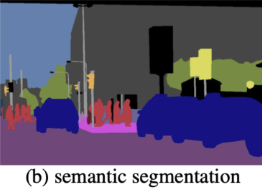
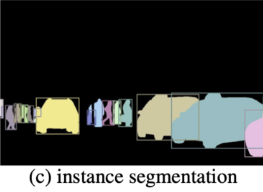
Semantic Segmentation Instance Segmentation Panoptic Segmentation Things와 Stuff를 모두 탐지
But Instance 구분 XThings만 탐지
But Instance 구분 OThings와 Stuff를 모두 탐지
And Instance 구분 O1. Supervised Learning
2. Unsupervised Learning1. Bottom-Up 방식
2. Top-Down 방식Instance Segmentation
- Bottom-Up Approches
- 이미지의 개별 픽셀을 감지하는 것부터 시작해, 픽셀들을 그룹화하며 객체를 탐지하는 방식
- ex. WT, InstanceCut, SGN, DeeperLab, Panoptic-DeepLab
- Top-Down Approches
- 이미지의 Bounding Box를 찾고 Binary Segmentation을 진진행하는 방식
- ex. Mask R-CNN, PANet, HTC, YOLACT

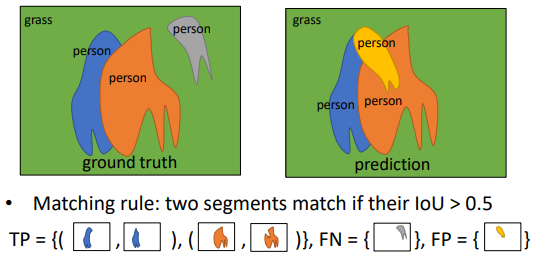
2) Panoptic Quality
Panoptic Segmentation은 Stuff까지 함께 Prediction하기 때문에 조금 다른 성능 평가 지표를 사용한다.
\[PQ = \frac{\sum \limits_{(p, q) \in TP} IoU(p, q)}{\|TP\| + \frac{1}{2} \|FP\| + \frac{1}{2} \|FN\|}\]
2. Instance Segmentation
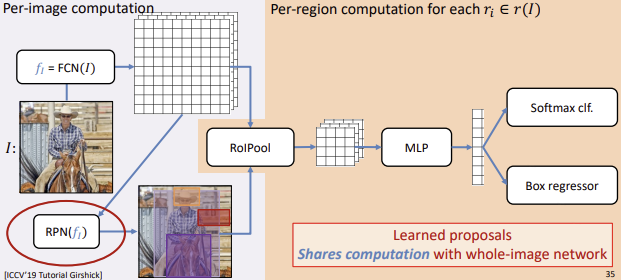
1) Mask R-CNN
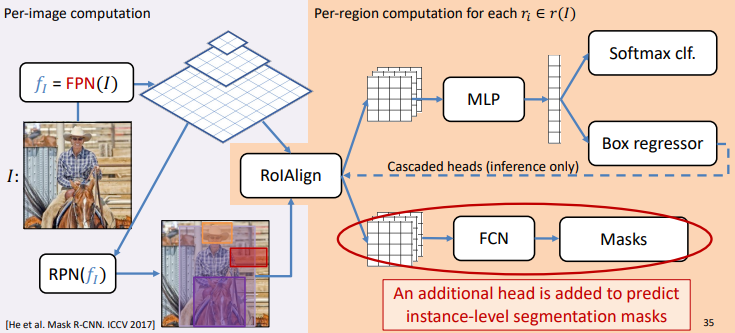
Purpose
Faster R-CNN Mask R-CNN
Top-Down Approches
$\rightarrow$ Faster RCNN에 Mask Branch(FCN) 추가Faster R-CNN의 RoI Pooling에서 발생하는 Quantization Error는 Detection Problem에서는 중요하지 않았다.
하지만 Segmentation에서는 Pixel단위의 정확도가 필요하다
$\rightarrow$ RoI Pooling대신 RoI Align 사용동작과정
- FPN (Feature Pyramid Network)
- 다양한 크기의 Object들을 감지하기 위해 FPN Backbone을 사용한다.
- RPN (Region Proposal)
- Feature Map에서 물체가 있을만한 곳(RoI)을 고른다.
(그 후, Objectness Score가 높은 K개를 골라 NMS를 수행해 준 후 다음 Layer로 전송)
- RoI Align
- RPN에서 찾은 Bounding Box후보들을 FPN의 Feature Map에 Projection한다.
이때, RoI Pooling을 사용하는 기존의 방식은 정확도가 떨어지기 때문에 RoI Align이라는 방법을 사용한다.
4. MLP 4. FCN 물체의 Bounding Box를 추정하기 위한 Layer
Box Regression, Classification을 수행Binary Segmentation을 위한 Layer
가장 기초적인 방법인 FCN 사용
$\rightarrow K$개(Class 개수)의 Feature Map을 출력(두 과정은 Parallel하게 동작한다.)
5. Multi-task Loss Function
: $L = L_{cls} + L_{box} + L_{mask}$ 를 통해 학습
(이때 $L{mask}$는 Binary Cross Entropy Loss이다.)_RoI Align
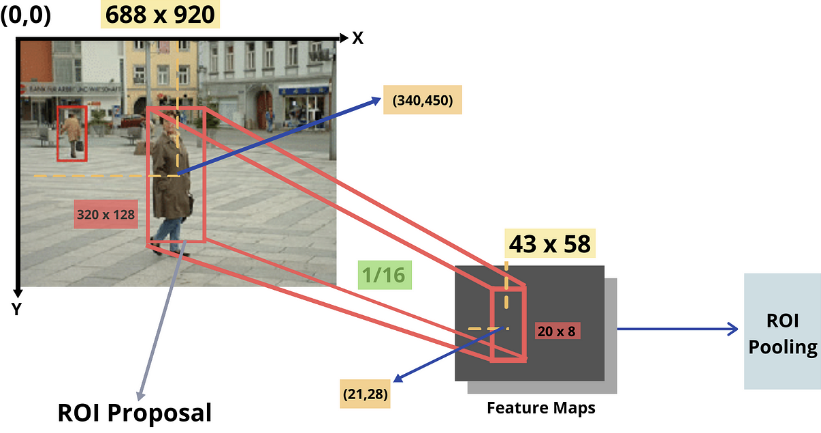
RoI Projection
RoI Pooling을 위해서 Bbox들을
Feature Mapdml Size에 맞게 Resize한다.
이때, 딱 나누어 떨어지지 않으면 반올림한다.
ex. 920/16 = 57.5 $\rightarrow$ 58RoI Pooling
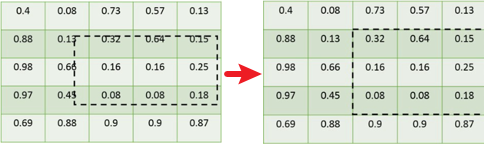
즉, 위의 RoI Projection에서의 반올림은
RoI Pooling에서 다음과 같은 Quantization
오류를 발생시킨다.
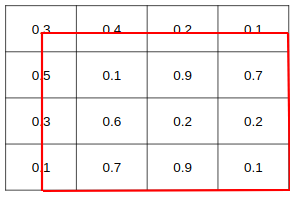
RoI Align 과정 RoI Pooling과 같이 Resize할 때, 반올림을 고려하지 않는다 RoI를 $2 \times 2$ Bin으로 나눈다. (예시) ⅰ. 각각의 Bin에 Sample Point 4개씩 생성
(논문에서는 각 cell의 3등분하는 점으로 잡았음)
(논문에 따르면 Point의 위치나 개수는 중요하지 않음)
ⅱ. 각 Sample Point마다 셀의 가로/세로 길이에 대해
Bilinear Interpolation으로 위치 계산각 Bin마다 Sample Point들을 Avg Pooling(Max Pooling)
.png)
.png)
.png)
3. Panoptic Segmentation
1) DETR for panoptic segmentation
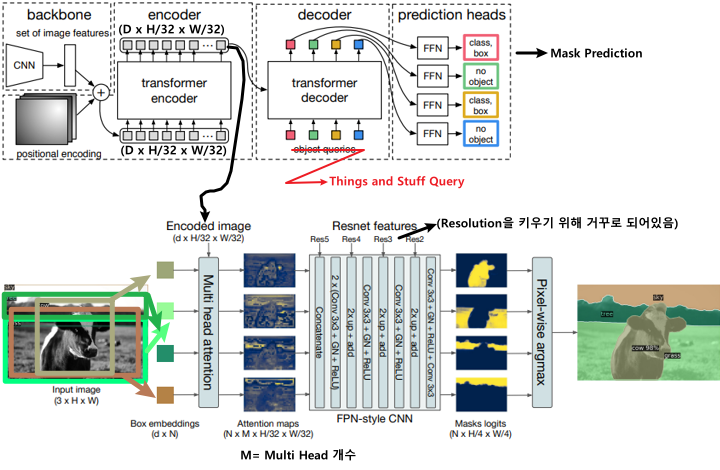
DETR논문에서는 Object Detection문제를 해결하며 Panoptic Segmentation에 대한 활용법도 제안하였다.
Purpose
Mask R-CNN과 마찬가지로 Object Detection Model인 DETR에서 Branch를 하나 추가해서 Segmentation도 풀 수 있게 만들어 보았다.
동작과정
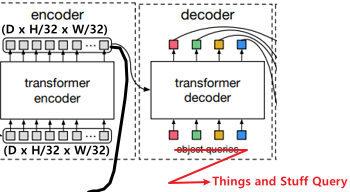
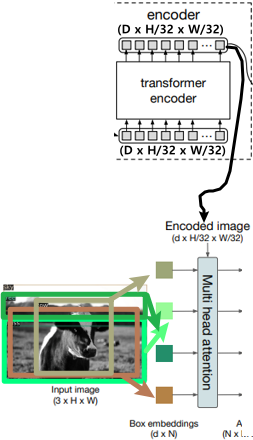
- Encode Image (as a Backbone)
$\rightarrow$ DETR의 Encoder에서 이미지의 Feature Map을 뽑아온다.
2. Classification 2. Segmentation Encoding된 Feature Map을 (Key-Value)로 사용하고
Things and Stuff Query와 Multi Head AttentionEncoding된 Feature Map을 (Key-Value)로 사용하고
Bounding Box와 Multi Head Cross Attention
- FPN-Style CNN (ex. Resnet)
- Attention Map을 다시 Up Sampling하기 위해 FPN과 같은 모델을 사용한다.
- Pixel Wise Argmax
- N(Query 개수)개의 Mask에 대해 Pixel Wise Argmax를 하여 Segmentation한다.
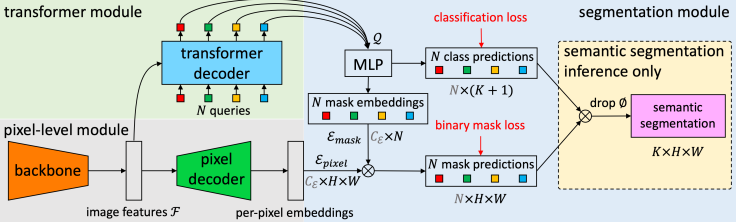
2) MaskFormer
(SAM:Segment Anithing Model과 같이 읽어보면 좋다고 함)
Purpose
일반적으로 Segmentation은 Pixel별로 분류하는 것으로 알려져있다.
하지만 이 논문의 저자는 DETR로부터 Segmentation은 Pixel별 분류가 아닌 Mask 분류라고 관점을 다르게 생각한 것 같다.즉, Pixel별 분류를 할때는 하나의 Loss를 사용하여 Class를 예측했지만
DETR과 같이 Transformer구조가 나오면서, N개의 Mask(Bbox)를 Parallel하게 생성할 수 있게 되었고,
이는 우리가 더이상 Pixel별 분류를 할 필요 없는 Mask Classification Task로 본다는 뜻인 것 같다. (맞나요…?)(MaskFormer는 위와 같은 생각을 갖고, DETR+Panoptic을 조금 더 깔끔하게 만든 모델이다.)