7. Segmentation(Semantic)
Segmentation
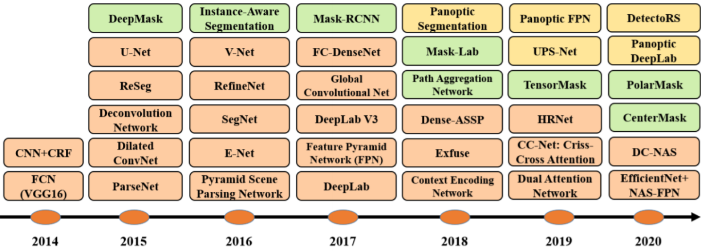
1. Background
1) Upsampling
UnPooling
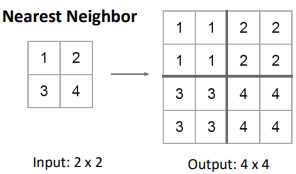
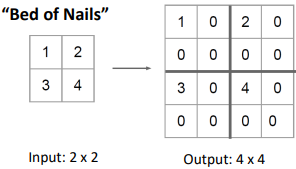
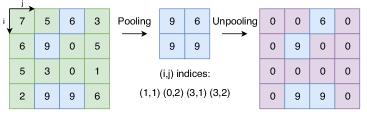
1. Nearest Neighbor 2. Bed Of Nails 3. Max Unpooling 자신의 값으로 채우는 방법 모두 0으로 채우는 방법 max값의 index를 기억했다가
Unpooling시 그 자리에 넣는 방법
(나머지는 0)
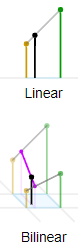
4. Bilinear Interpolation 5. Bicubic Interpolation 선형 보간법
- 두 점 사이의 점에 대해 선형 함수를
사용해 계산하는 방법(내분 점)
ⅰ. 미지수를 설정해 1차함수 설정
ⅱ. 미지수가 2개이므로 2개의 점에 대해 계산삼차보간법
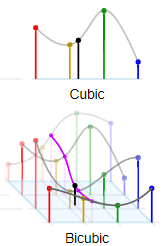
- 두 점 사이의 점에 대해 3차함수를
사용해 계산하는 방법
ⅰ. 미지수를 설정해 3차함수 설정
ⅱ. 미지수가 4개이므로 4개의 점에 대해 계산
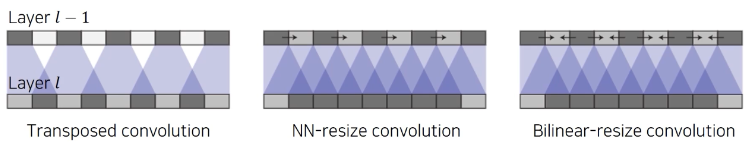
6. Transpose Convolution Learnable Upsampling 방식으로
적절한 Padding, Stride, Convolution을 이용해 Unsampling하는 방법(Overlap Issue)
일반적인 Transposed Convolution은 일정 간격마다 밝기가 달라지는 Overlap Issue가 발생한다.
이 단점을 해결하기 위해 주로 Bilinear등으로 Upsampling을 한 후에 Convolution을 수행한다.(UnPooling은 Channel By Channel로 진행된다.)
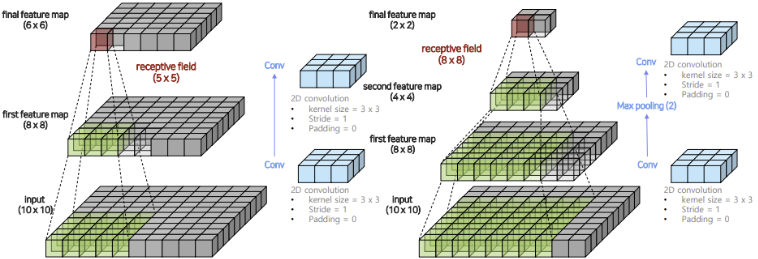
2) Dilated Convolution
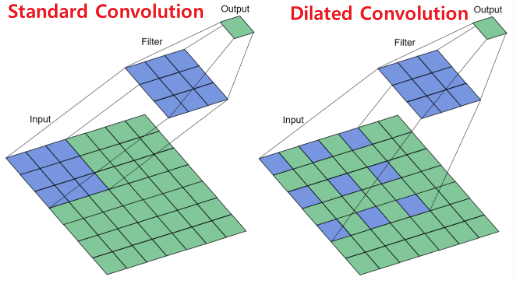
Receptive Field를 키우는 방법는 대표적으로 다음의 두개가 존재한다.
1. Convolution + MaxPooling 2. Dilated(Atrous) Convolution ⅰ. Convolution $\rightarrow$ Convolution
ⅱ. Convolution $\rightarrow$ MaxPooling $\rightarrow$ Convolution
(방법 (ⅱ)가 더 큰 Receptive Field를 갖는다.)
Dilated를 통해 적은 수의 DownSampling으로도
Receptive Field의 크기를 효과적으로 키운다.Receptive Field를 매우 키울 수 있지만 정보의 손실이 많아
Upsampling시 낮은 Resolution을 갖는다.Max Pooling의 단점을 보완한 방법 DilatedNet
Dilated Convolution을 DeepLab V1보다 조금 더 잘 활용하여 구성한 모델로 Dilated Net이 있다.
Dilated Net은 다양한 Dilate비율을 활용하고,
마지막에는 여러 Dilate비율을 가지고 예측한 후 합치는 Basic Context Module이 가장 큰 특징이다.
2. Semantic Segmentation
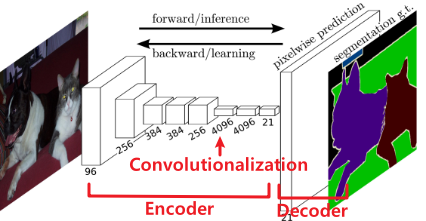
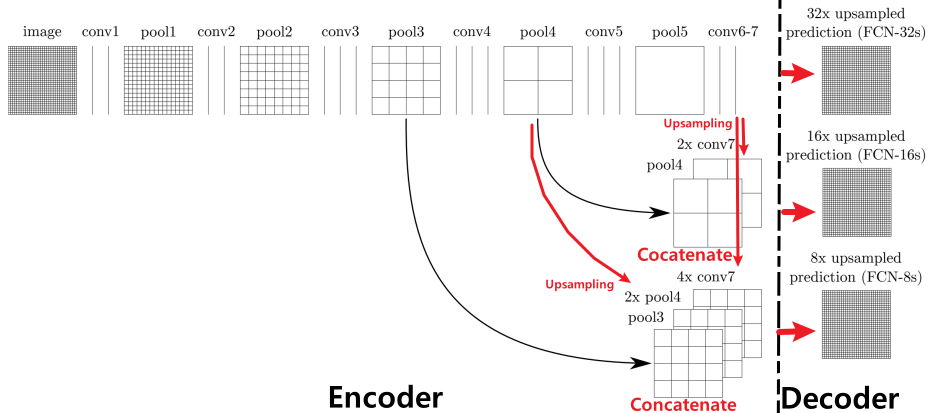
1) FCN(Fully Convolution Network)
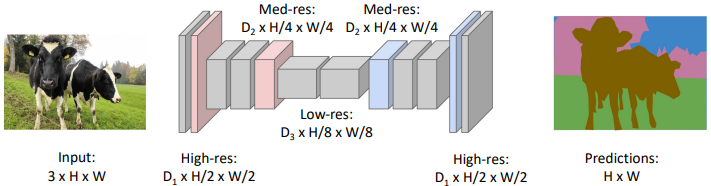
FCN은 Fully Convolutional Networks의 약자로 FC Layer를 사용하지 않고 Convolution Layer만을 사용하여 이미지를 처리하는 Network라는 특징이 있다.
Purpose
만약 $3 \times 3$ Convolution만을 사용해 Spatial Dimension을 변화시키지 않도록
Model을 설계하면 Layer대비 Receptive Field의 크기가 작아지기 때문에
모델이 이미지의 전반적인 Context를 파악할 수 없다.
$\rightarrow$ Encoder-Decoder Design일반적인 Classification 모델은 마지막에 Fully Convolution Layer를 사용한다.
이때, Flatten이 필요하기 때문에 위치정보를 유지할 수 없다.
$\rightarrow$ Convolutionalization
(이미지를 줄이지 않고 $1\times1$ Convolution만을 사용해 채널크기만 변경하는 것)동작과정
Encoder Decoder $3 \times 3$ Convolution을 사용해 Down Sampling한다.
※ Skip Connection
마지막 Feature Map은 큰 Receptive Field를 가짐
$\rightarrow$ Detail한 정보를 갖지 못함
즉 이를 위해 Skip Connection이 필요하다.
ⅰ. Concatenate
: Elementwise 덧셈인 FPN과 다르게 합침
ⅱ. Upsampling
: 크기를 맞추기 위해 Bilinear UpsamplingFCN에서는 Bilinear로 한번에 Up Sampling해 주었다.
(FCN-32s는 Decoder에서 32배 Upsampling했다는 뜻)문제점
객체의 크기가 크거나 작은 경우 여전히 예측을 잘 하지 못함
객체의 디테일한 모습을 찾지 못함
2) U-Net
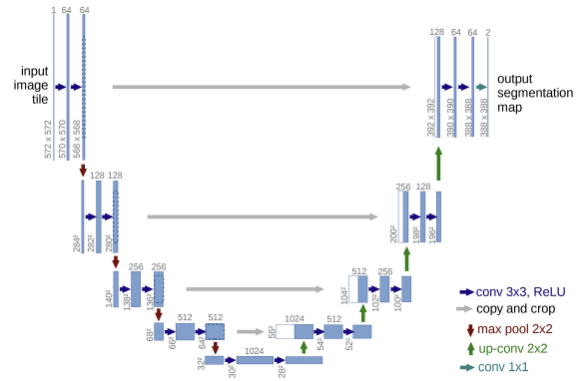
Purpose
FCN은 낮은 Resolution을 가진 Featuremap을 단 한번의 UpSampling을 통해 키워주었다.
$\rightarrow$ Contracting Path와 Expanding Path를 나누어 점진적인 Upsampling 수행FCN은 Skip Connection을 잘 활용하지 못했다.
$\rightarrow$ 각 Layer에 대응되도록 Skip Connection 설계동작과정
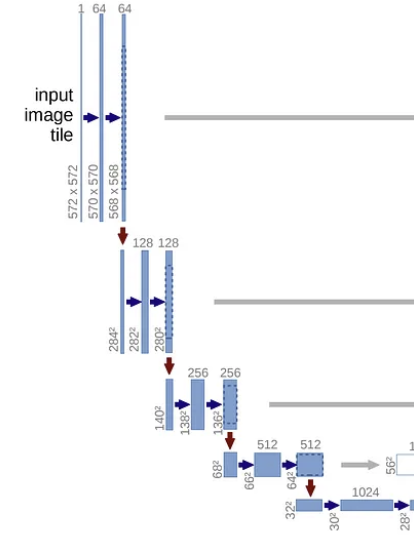
Contracting Path Expanding Path 1. 각 Step마다 두번의 $3 \times 3$Convolution Layer
2. 각 Step마다 $2 \times 2$ Max Pooling
3. 각 Step마다 Channel이 2배1. 각 Step마다 두번의 $3 \times 3$Convolution Layer
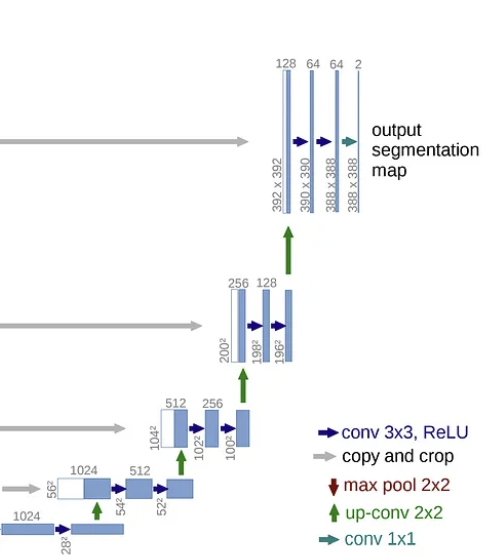
2. 각 Step마다 $2 \times 2$ Up Convolution
3. 각 Step마다 Channel이 절반$\therefore$ Pooling시에 Channel을 늘려
해상도가 낮아지는 것을 보완$\therefore$ Upsampling시 대응되는
Contracting Path의 Feature를 Concatenate
(Concatenate시 대상이 되는 두 Feature Map의
크기가 다르다는 문제가 있다.
$\rightarrow$ 가운데 부분을 Crop하여 Paste)주의점
Down Sampling시 홀수 크기의 Feature Map이 존재하면 Upsampling시에 본래의 크기를 알 수 없다.
즉, 중간에 어떤 Feature맵도 홀수의 크기를 가지면 안된다.
3) Deeplab V1
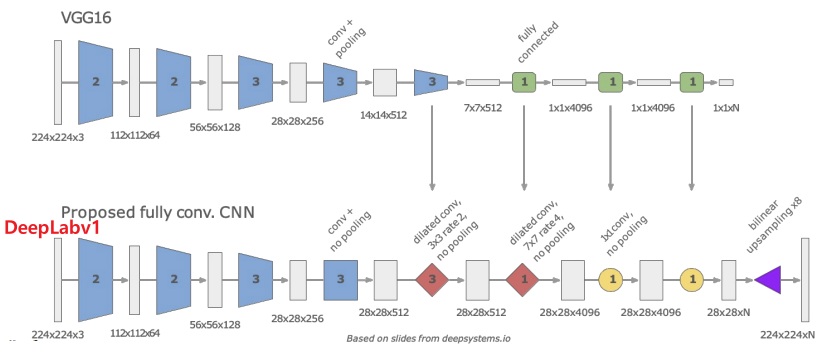
Purpose
MaxPooling을 사용해 Receptive Field를 키우는 방법은 정보의 손실이 너무 많다.
$\rightarrow$ Dilated ConvolutionBi-Linear Interpolation으로만 Upsampling하면 픽셀단위의 정교한 Segmentation이 불가능하다
$\rightarrow$ CRF동작과정
DeepLab V1의 동작과정은 전반적으로 FCN과 비슷하다.
- Reduce Feature Map
- FCN과 마찬가지로 Convolution + Maxpooling으로 Feature Map을 $\frac{1}{8}$으로 줄인다.
- Dilated Convolution
- 그 뒤부터는 Covolutionalization이 아닌, Dilated Convolution을 사용해
Feature Map의 크기는 유지하면서도 Receptive Field를 늘린다.
- Upsampling
- Bilinear Interpolation을 사용해 Up Sampling한다.
- Post Processing
- Bilinear Interpolation을 통해 한번에 Upsampling할 경우 정교한 Segmentation이 불가능하다.
$\rightarrow$ DeepLab V1에서는 이러한 문제를 해결하기 위해 Dense CRF라는 후처리 기법을 도입하였다.$\therefore$ FCN과 전반적인 동작과정은 비슷하지만
Dilated Convolution덕분에 Receptive Field를 효과적으로 늘릴 수 있었고
CRF라는 기법 덕분에 효과적인 성능향상을 보여주었다.CRF
CRF는 입력으로 (원본 이미지, Segmentation Map) 쌍을 받고 다음과 같은 원리로 각 픽셀의 확률값을 조절한다.
- 이미지의 색상이 유사한 픽셀이 가까이 있으면 같은 범주에 속한다.
- 이미지의 색상이 유사해도 픽셀 사이의 거리가 멀면 다른 범주에 속한다.
동작과정 설명 각 픽셀 별 클래스 예측값을 구한다. Class하나를 골라 이 확률값과 이미지를
CRF에 입력하고 이 과정을 반복수행한다.다른 Class에 대해서도 같은 과정을 수행한다. 위 결과들을 합친다.

.png)
.png)
.png)
.png)
4) Deeplab V2
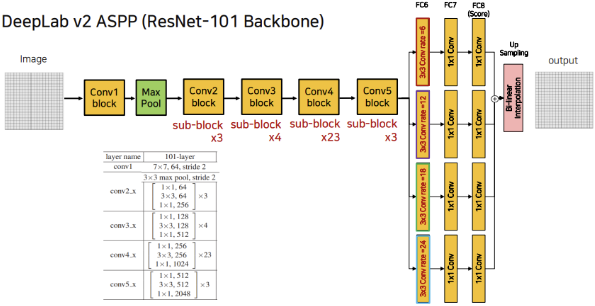
Purpose
- DeepLab V1은 Single Path의 Dilated Convolution을 사용했다.
$\rightarrow$ ASPP를 사용해 더 다양 Receptive Field를 계산하자(또, DeepLab V1에서는 VGG를 Backbone으로 사용했지만 V2는 ResNet-101을 사용한다.)
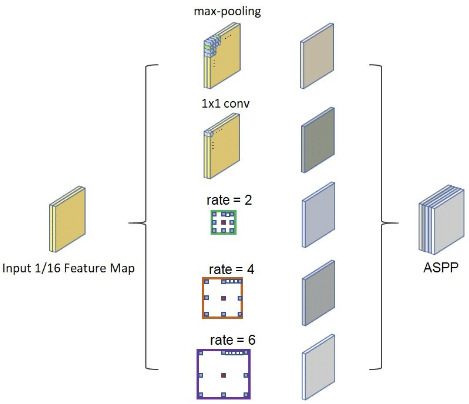
ASPP(Atrous Spatial Pyramid Pooling)
ASPP는 Feature Map을 다양한 Receptive Field를
갖도록 Dilated Convolution등으로 계산하고
이 Feature Map을 Concat한다.
이때, 서로 다른 크기의 Feature Map이 생산되는데
보통 가장 큰 Feature Map에 맞게
Bilinear Interpolation으로 Upsampling한 후
Concatenate해 준다.
–todo: Deconv Net, FC Dense Net, PSP Net DeepLab V3, DeepLab V3+ –