[Paper Review] Aggregated Residual Transformations for Deep Neural Networks
Source
Contents
0. Abstract
우리는 이미지 분류를 위한 간단하고 고도로 효율화된 network architecture를 소개한다. 우리의 network는 building block구조를 반복하여 만들어지고 이는 동일한 topology를 갖는”set of transformations”를 집계하는 역할을 한다. 이러한 간단한 설계는 몇가지 하이퍼파라미터만 설정하면 되는, 동질한, multi-branch architecture를 제공한다. 이 전략은 depth와 width외에도 cardinality라는 새로운 dimension을 제공한다.(cardinality == size of the set of transformation). 우리는 ImageNet-1K 데이터셋에서, 복잡도를 유지하는 제약 조건에서도 카디널리티를 증가시키는 것이 Classification 정확도를 향상시킬 수 있음을 실험적으로 보여주었다. 게다가 Capacity를 늘릴 때, 깊이를 더 깊게 하거나 폭을 넓히는 것보다 cardinality를 늘리는 것이 더 효과적이다. ResNeXt라고 불리는 우리의 모델은 ILSVRC 2016 Classification에 출전한 모델로 이 대회에서 2등을 차지하였다. 우리는 ResNeXt를 ImageNet-5K 데이터셋과 COCO 탐지 데이터셋에서 추가로 실험한 결과, ResNet 대비 더 나은 성능을 보여주었습니다.
1. Introduction
Previous Work(VGG, ResNet)
Visual Recognition에 대한 연구는 feature engineering에서부터 network engineering으로 전환되고 있다. SIFT, HOG와 같은 전통적인 hand designed feature와 달리 대규모 데이터와 인공신경망으로 부터 학습된 feature는 훈련 과정에서 사람의 최소한의 개입만을 필요로 하고, 다양한 recognition task에 전이될 수 있다. 그럼에도 불구하고 사람들은 표현학습을 위한 더 나은 architecture 설계를 위해 노력하고 있다.
Architecture를 설계할 때, 특히 network에 많은 layer가 있을 때, hyper-parameter의 개수의 증가로 인해 점점 어려움을 겪고 있다. VGG-nets은 동일한 구조의 building blocks를 반복해서 쌓아, 매우 깊은 네트워크를 간단하지만 효과적으로 설계하였다. 이러한 전략은 ResNet에 의해 계승되었다. 이 간단한 규칙은 hyper parameter의 자유도를 줄이고, depth가 신경망의 본질적인 차원이 되도록 한다. 게다가 우리는 이러한 단순한 규칙이 하이퍼 파라미터에 의해 특정 데이터셋에 overfitting되는 위험을 줄일 수 있다고 생각한다. VGG-nets과 ResNets의 강건함은 다양한 visual recognition task에서 증명되었을 뿐만 아니라 non-visual task에서도 입증되었다.
Previous Work(Inception)
VGG-nets과 달리 Inception 모델 계열은 신중하게 설계된 topology가 낮은 Complexity로도 더 높은 정확도를 달성할 수 있음을 보여주었다. Inception모델은 시간이 지나면서 발전했지만, 가장 중요한 공통점은 “Split-transform-merge”전략이다. Inception module에서 입력은 ⅰ) $1 \times 1 Conv$에 의해 몇개의 낮은 차원으로 embedding되고, ⅱ) $3 \times 3 Conv, 5 \times 5 Conv$을 사용해 변형된 후, ⅲ) concatenation에 의해 합쳐진다. 이것은 architecture의 solution space는, 고차원 embedding에서 동작하는 $5 \times 5 Conv$와 같은 큰 layer의 Solution space의 subspace임을 알 수 있다. Inception module의 “Split-transform-merge”동작은 상당히 낮은 계산 복잡도로도 크고 밀집된 layer의 표현력을 기대할 수 있게 한다.
Problem
우수한 정확도에도 불구하고 Inception 모델의 구현은 복잡한 요소들이 많다. 예를들어 필터의 수, 크기가 각각의 변환에 대해 조정되고 단계별로 customized된다. 비록 이러한 요소들을 신중하게 조합하면 훌륭한 신경망을 만들 수 있지만, 특히 많은 요소들과 하이퍼파라미터를 설계해야할 때, Inception architecture를 새로운 datset과 task에 맞게 학습시키는 것은 불분명하다.
Approaches
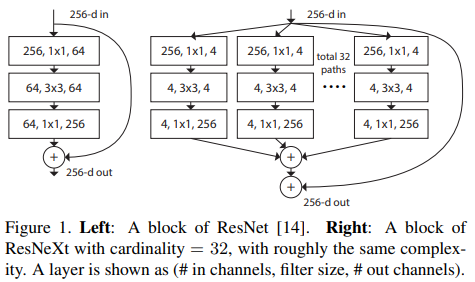
이 논문에서 우리는 VGG/ResNet의 layer반복 전략을 채택해 “Split-transform-merge”을 간단하고 확장 가능한 방식으로 만드는 간단한 architecture를 제안한다. 우리의 network안의 module은 낮은 차원의 embedding들에 대해 각각 transformation의 집합을 수행하고, 출력은 Summation으로 aggregate된다. 우리는 이 idea의 간단한 구현을 추구하여, 위의 그림과 같이 transformation이 모두 같은 topology를 사용할 수 있게 하였다. 이 디자인은 특수한 설계 없이도 많은 수의 transformation으로 확장할 수 있게 해준다.
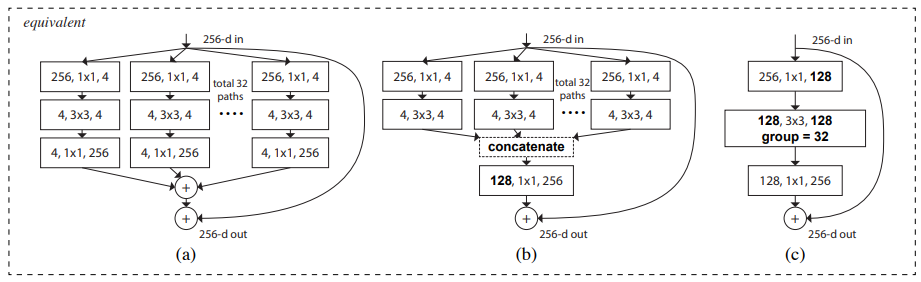
흥미롭게도 이러한단순한 상황에서 우리는 우리의 모델이 두가지 동등한 형태를 가질 수 있음을 보여준다.
(b): 여러 경로를 병합한다는 점에서 Inception-ResNet모듈과 유사해 보인다. 하지만 우리의 module은 모든 경로가 동일한 topology를 공유한다는 점에서 inception 모듈과 다르다. 때문에 경로의 수는 독립적인 요소로써 실험된다.
(c): 더 간결하게 우리의 모듈은 grouped convolution으로 해석될 수 있다. 하지만 이는 engineering 타협안(계산 비용을 줄임)으로써 사용된다.
Effect
우리는 aggregated된 transfomation이 계산 복잡도와 모델 크기를 같게 유지했음에도 불구하고 기존의 ResNet을 능가한다는 실험적으로 입증했다. (위에서 resnext와 resnet의 FLOPs와 파라미터 수는 같다.) 우리는 capacity를 증가시켜 정확도를 쉽게 늘리는 것은 쉽지만, 이를 유지하거나 줄이면서 정확도를 늘리는 것은 문헌에서도 드물다는 것을 강조한다.
우리의 방법은 set of transformation의 크기인 cardinality가 width나 depth외에도 중요하고 구체적인, 측정 가능한 차원임을 나타낸다. 실험은 cardinality의 증가가 network를 깊고 넓게 만드는 것보다 더 효과적으로 정확도를 올리는 방법임을 증명하였다. 특히 이는 depth나 width를 늘리는 것의 이득이 점차 감소하는 것을 보이기 시작할 때 효과적이였다.
Conclusion
ResNeXt라고 이름 붙인 우리의 신경망은 ImageNet 분류 데이터셋에서 ResNet-101/152, ResNet-200, Inception-v3, Inception-ResNet-v2보다 더 우수한 성능을 보였다. 특히, 101-레이어 ResNeXt는 ResNet-200보다 더 나은 정확도를 달성하면서도 복잡도는 50%에 불과하다. 게다가, ResNeXt는 모든 Inception 모델보다 훨씬 간단한 설계를 보여준다. ResNeXt는 ILSVRC 2016 Classification task에 제출된 우리의 모델의 기반이 되었으며, 이 대회에서 2위를 차지했다. 이 논문은 ResNeXt를 더 큰 ImageNet-5K 데이터셋과 COCO 객체 탐지 데이터셋에서 추가로 평가했으며, ResNet 모델 대비 일관되게 더 나은 정확도를 보였다. 우리는 ResNeXt가 다른 visual 및 non-visual recognition 작업에도 잘 일반화될 것으로 기대한다.
2. Related Work
## resnet relatedwork