[Paper Review] Rich feature hierarchies for accurate object detection and semantic segmentation
Source
Summary
이 논문의 주요 쟁점은 다음과 같다. 기존의 detection은 다음과 같이 풀어나갔다.
feature기반의 detector
→ 더이상의 성능 향상이 어려움(약간의 변형만 가지고 개선해왔음)regression detector
→ 실제로는 잘 동작하지 않았음sliding window detector with CNN
→ receptive field가 커진다는 문제
즉, 이 논문에서는 위의 방법들이 아닌 새로운 방식을 고안했어야 했다. 이를 위해서 사용한 것이 “recognition using region” 방식이다. 간단히 말하면 어떤 방식으로든 물체가 있을법한 region을 찾아서 이를 CNN으로 recognition하자는 것이다. 내 생각에는 위의 모든 방법을 합친다는 것이 가장 큰 Idea같다.
실제로 동작 과정은 각 방법들이 서로의 단점을 보완해주는 방식이 된다.
우선 sliding window with CNN으로 Image에서 한번에 object의 위치를 찾으면 receptive field가 커진다. 그렇다면, feature기반의 detector로 일단 region을 뽑아내고, 여기에 sliding window with CNN을 사용해보자는 것이다. CNN의 입력이 제한되므로 receptive field가 커지는 것을 막을 수 있다.
또한 이렇게 CNN을 사용하게 되면 당시에 Object detection dataset이 적었던 문제를 해결할 수 있지 않을까? 라고 생각이 들 수 있다. CNN은 대용량 dataset이 존재하는 Classification에 적합하게 발전해 왔고, 이를 detection으로 가져왔으니까 이 장점을 활용하고 싶어질 수 있다.
이러한 idea에서 출발해 ImageNet으로 사전학습한 후에, 적은 개수의 dataset인 PASCAL VOC로 다시 학습시켜봤더니 효과가 있었다는 것이 결론인 것 같다.
그래서 결국 나의 결론은 다음과 같다.
- Previous work에 존재했던 단점들을 상호 보완하는 과정으로 활용해보자.
- Previous work의 장점을 가져올 때, Current work의 단점을 보완하는 방법으로 활용해 보자.
어떤 previous work도 단점만 있는 것이 아니다. 장점을 잘 찾아내서 이를 활용하는 것이 중요한 것 같다.
Contents
0. Abstract
PASCAL VOC dataset에서 측정된 객체 탐지 성능은, 지난 몇 년동안 정체 상태에 있었다. 여기서 최고 성능을 보이는 방법들은 일반적으로 여러 low-level image feature와 high-level context를 결합한 복잡한 앙상블 시스템들이다. 이 논문에서는 이전의 VOC 2012에서 가장 좋은 결과의 mAP를 30%올려 53.3%를 달성한 간단하고 확장 가능한 detection algorithm을 제안한다. 우리의 방식은 두 가지 핵심 insight를 결합한다. (1) high-capacity CNN을 object를 localize하고 분류하기 위한 bottom-up region proposal로 사용할 수 있다는 점, (2) labeled training data가 부족할 때, auxiliary task에서 supervised training을 미리 한 후에, domain-specific finetuning을 하면 상당한 성능 향상을 도와준다. 우리는 region proposal을 cnn과 결합하였기 때문에 이 방식을 RCNN:Region with CNN features라고 부른다. 우리는 또한 R-CNN을 최근 제안된 OverFeat과 비교한다. OverFeat은 cnn을 기반으로 하는 Sliding window detector이다. 우리는 R-CNN이 200개의 Class가 포함된 ILSVRC2013 detection dataset에서 OverFeat을 매우 큰 폭으로 능가한다는 것을 발견했다.
1. Introduction
Previous Work - SIFT
Features는 중요하다. 지난 10년동안 다양한 visual recognition task의 발전은 주로 SIFT와 HOG에 기반을 두고 있다. 그러나 만약 대표적인 visual recognition task인 PASCAL VOC object detection의 성능을 살펴보면, 2010~2012년동안 진전이 매우 느렸으며, 주로 ensemble system과 기존 성공적인 방법에 약간의 변형만을 가지고 소폭의 개선만 이루어 왔다.
SIFT와 HOG는 blockwise orientation histogram으로, 영장류의 시각 경로의 첫 번째 피질 영역인 V1의 Complex cell과 연관지어볼 수 있다.그러나 우리는 recognition이 여러 하위 경로에서 이루어진다는 것을 알고 있고, 이는 visual recognition에 더 유익한 feature를 계산하기 위한 multi-stage의 계층구조임을 암시한다.
Previous Work - CNN
Fukushima의 “neocognitron”은 생물학적으로 영감을 받은 계층적이고 shift-invariant한 pattern recognition model로 위의 과정을 위한 초기 시도였다. 하지만 neocognitron은 supervised training algorithm이 부족했다. Rumelhart등의 연구를 바탕으로 LeCun등은 Backpropagation을 이용한 SGD가 CNN을 훈련하는데 효과적임을 보여주었다. CNN은 neocognitron을 확장한 모델이다.
CNN은 1990년대에 널리 사용되었으나 SVM의 등장으로 인기가 줄어들었다. 2012년 Krizhevsky등은 ILSVRC에서 매우 높은 분류 정확도를 보여주며 CNN에 대한 관심을 다시 불러 일으켰다. 이들의 성공은 120만개의 Labeled image를 LeCun이 제안한 몇가지 개선과정(ReLU, Dropout)을 거친 큰 CNN을 학습시킨 결과이다.
ImageNet 결과의 중요성은 ILSVRC 2012 워크숍에서 활발히 논의되었다. 핵심 쟁점은 다음과 같이 요약될 수 있다: ImageNet에서의 CNN 분류 결과가 PASCAL VOC에서 Object Detection에서도 비슷한 성능을 가져올 수 있을까?
우리는 Image Classification과 Object Detection의 간극을 메움으로써 이 질문에 답한다. 이 논문은 CNN이 HOG와 같은 단순한 feature 기반 system에 비해 PASCAL VOC에서 object detection 성능을 극적으로 향상시킬 수 있음을 처음으로 보여준다. 이 결과를 달성하기 위해 우리는 2가지 문제에 초점을 맞추었다: ⅰ) deep network를 사용해 object를 localizing하고, ⅱ) 소량의 annotated detection data를 사용해 high capacity model을 학습시키는 것이다.
Problem
Image Classification과 달리 detection은 image내에서 많은 object를 localizing해야한다. 하나의 접근법은 localization을 regression으로 바꾸는 방식이다. 그러나 szegedy등의 연구에서는 이 전략이 실제로는 잘 동작하지 않음을 보였다. (VOC 2007에서 우리의 방식이 58.5%의 정확도를 달성한 것과 달리, 30.5%의 mAP를 기록했다.) 이에 대한 대안은 sliding window detector를 만드는 것이다. CNN은 face나 pedstrian과 같은 객체 category에서 최소 20년 동안 이러한 방식으로 사용되어 왔다. 높은 해상도를 유지하기 위해 이러한 CNN은 일반적으로 2개의 convolutional과 pooling만을 가진다. 우리는 또한 sliding window 접근 방식을 채택했다. 그러나 우리의 네트워크에서 5개의 convolutional layer를 가지고 있는 상위 계층의 unit들은, 입력 이미지에서 매우 큰 receptive field와 stride를 가지기 때문에 sliding window paradigm에서 정확한 localization을 수행하는 것은 기술적 어려움으로 남아있다.
정리하자면 기존의 detection 문제는 다음과 같이 해결했었다.
Regression
단점: 연구 결과 실제로 잘 동작하지는 않음Sliding window detector
단점: convolution 사용시 상위 layer의 unit들은 큰 receptive field를 가져 localization을 수행하기 어렵다.
Approach - roi
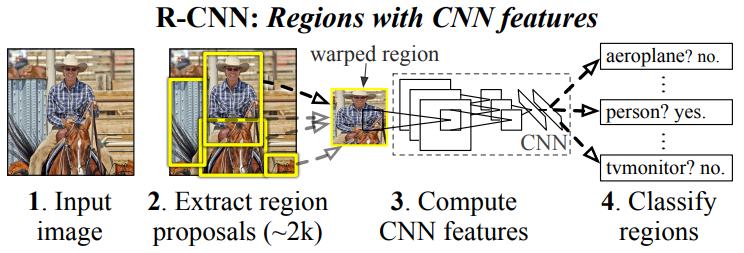
대신에 우리는 CNN localization 문제를 object detection과 semantic segmentation에서 성공적이었던 “recognition using region” paradigm을 활용해 해결한다. ⅰ) test시, 우리의 방식은 입력 이미지에 대해 약 2000개의 category-independent region proposal을 생성한다. ⅱ) 그리고 각 proposal에서 CNN을 사용해 고정된 길이의 feature vector를 추출하고, ⅲ) 각 영역을 category-specific linear SVM으로 분류한다. 우리는 region의 모양과는 관계없이 각 region proposal로부터 고정된 크기의 CNN입력을 계산하기 위한 간단한 기법을 사용한다. 위의 그림은 우리의 방법에 대한 overview를 보여준다. 우리의 system은 region proposal과 CNN을 결합하기 때문에 우리는 이 방식을 R-CNN: Regions with CNN feature라고 명명한다.
본 논문의 업데이트된 버전에는, 200개의 class가 포함된 ILSVRC2013 Detection dataset에서 R-CNN을 실행하여 최근 제안된 OverFeat과의 직접적인 비교를 제공한다. OverFeat은 sliding-window CNN을 detection을 사용하고, 지금까지 ILSVRC2013 detection에서 가장 좋은 방식이었다. 우리는 R-CNN이 31.4%의 mAP로 24.3% mAP의 OverFeat을 상당히 능가하는 것을 보여주었다.
Approach - learning paradigm
detection에서 직면하는 두번째 과제는 labeled data가 부족하고, 현재 사용 가능한 데이터의 양이 CNN을 훈련하기에 충분하지 않다는 점이다. 이러한 문제의 전통적인 해결책은 unsupervised pre-training을 사용한 후에 supervised finetuning을 하는 것이다. 이 논문의 두 번째 contribution은 데이터가 부족한 상황에서 high-capacity의 CNN을 학습하기 위해, supervised pretraining을 ILSVRC 큰 보조 dataset으로 수행한 후, PASCAL같은 small dataset으로 domain-specific fine-tuning하는 것이 효과적인 paradigm이라는 것을 보여주었다는 점이다. 우리의 실험에서 detection을 위한 fine-tuning은 mAP 성능을 8% 향상시켰다. fine-tuning이후, 우리의 system은 VOC2010에서 mAP 54%를 달성하였으며 이는 highly-tuned된 HOG기반 DPM의 33%와 비교되는 결과이다. 우리는 또한 Donahue 등의 동시대 연구를 독자들에게 소개하며, 이 연구는 Krizhevsky의 CNN이 (미세 조정 없이) blackbox feature extractor로 사용될 수 있으며, scene classification, fine-grained sub-categorization, domain adaptation을 포함한 여러 recognition task에서 우수한 성능을 보여줄 수 있음을 입증하였다.
또한 우리의 system은 매우 효율적이다. class별 계산은 합리적이고 작은 matrix-vector 곱셈과 greedy한 NMS만을 포함한다. 이 계산 속성은 모든 category에 걸쳐 공유되는 feature이고, 이전에 사용된 region feature보다 2자리수가 낮은 차원을 갖게 된다.
우리의 접근법의 failure mode를 이해하는 것은 이를 개선하는데 중요하고, 따라서 우리는 Hoiem등의 detection analysis tool의 결과를 보고한다. 이 분석의 즉각적인 결과로, 우리는 간단한 bbox regression 방식이 mislocalization을 상당히 줄인 것을 입증하였다.
기술적 세부사항을 논의하기 전에, 우리는 R-CNN이 region에서 동작하기 때문에, sementic segmentation으로 확장이 가능하다는 것이 자연스럽다는 것을 언급한다. 약간의 수정으로, 우리는 PASCAL VOC Segmentation작업에서도 경쟁력있는 결과를 달성하였고, VOC 2011 test set에서 분류 정확도 47.9%를 달성하였다.
정리하자면 이 논문의 큰 기여점은 다음과 같다.
recognition using regions paradigm
ⅰ) Image에서 region proposal 생성
ⅱ) 각 proposal에서 CNN을 사용해 feature vector 추출
ⅲ) 각 feature vector를 linear SVM으로 분류pretraining
detection dataset이 매우 부족한데, 이를 해결하기 위해 large dataset으로 pretrain된 CNN을 사용하면 된다.
2. Object Detection with R-CNN
우리의 detection system은 3가지 module로 구성되어 있다. 첫 번째는 category-independent region proposal을 생성한다. 이 proposal들은 우리의 detector가 사용할 수 있는 detection candidate의 집합으로 정의한다. 두 번째는 각 region에서 고정된 길이의 feature vector를 추출하는 large convolutional neural network이다. 세 번째는 class-specific한 linear SVM들의 집합이다. 이 section에서, 우리는 각 모듈에 대한 design decision을 제시하고, test할 때 사용방법을 설명하며, 이 파라미터가 어떻게 학습되는지에 대한 세부사항과, PASCAL VOC 2010-12, ILSVRC2013에서의 결과를 보여줄 것이다.
2.1 Module design
ⅰ) Region proposals
최근 다양한 논문에서 category-independent한 region proposal 생성 방식이 제안되었다. 예를 들어 다음이 있다.
- Objectness
- Selective search
- Category-independent object proposal
- CPMC
- multi-scale combinatorial grouping
- ciresan et al
이들은 규칙적으로 분리된 정사각형의 cop에 CNN을 적용하여 분열을 탐지하고, 이는 region proposal의 특별한 사례이다. R-CNN은 특정 region proposal의 방식에 구애받지 않지만, 우리는 이전 연구들과의 비교를 위해 Selective Search를 사용한다.
ⅱ) Feature Extraction
우리는 region proposal을 CNN의 Caffe구현을 통해 4096 차원의 feature vector를 추출한다. Feature는 평균이 제거된 $227 \times 227$ RGB image를 5개의 Convolutional layer와 2개의 FC layer를 foward propagate하여 계산된다.
region proposal에 대한 feature를 계산하기 위해서, 해당 영역의 이미지 데이터를 CNN과 호환되는 형태로 변환하여야 한다. (CNN은 고정된 $227 \times 227$의 입력 크기를 필요로 한다.) 임의의 모양의 region에서 우리는 가장 단순한 것을 선택한다. region 후보지의 size나 aspect ratio와 관계없이 우리는 해당영역 주위의 tight bounding box내의 모든 pixel을 설계된 크기로 warping한다. warping전에, 우리는 tight bounding box를 팽창시켜 box주변에 정확히 p개의 pixel의 왜곡된 문맥이 있도록 한다.(p=16 사용)
ⅲ) SVM
2.2 Test-time detection
test time에 우리는 image에서 2000개의 region propoasl을 추출하기 위해, selective search를 실행한다. (모든 실험에서 selective search의 “fast mode”를 사용한다.) 우리는 각 proposal을 warp한뒤 CNN에 순전파하여 feature를 계산한다. 그리고 각 class에 대해, 우리는 해당 class에 대해 학습된 SVM을 사용해 Feature VECTOR를 점수화한다. 이미지에서 점수화된 모든 영역에서 우리는 NMS를 적용한다. 이는 높은 점수를 받은 selected region과 IoU가 학습된 threshold보다 큰 경우 해당 영역을 제거하는 방식이다.
Run-time analysis
2가지 특성이 detection을 효과적으로 만들어 준다. 우선, 모든 category에서 모든 CNN parameter가 공유된다. 둘째로, CNN에 의해 계산된 feature vector는 bag-of-visual word encoding같은 보통의 접근법에 비해 저차원을 갖는다. 예를 들어 UVA detection system에서 사용된 feature는 우리의 system보다 2자리수 더 크다.
이러한 sharing의 결과로, region proposal과 feature를 계산하는데 소요되는 시간(이미지당 GPU에서 13초, CPU에서 53초)은 모든 class에 걸쳐 분산된다. Class별 계산은 feature와 SVM weight간의 내적과 NMS만 포함된다. 실제로, 이미지에 대한 모든 내적은 하나의 maxrix-matrix product로 묶일 수 있다. 이 Feature matrix는 전형적으로 $2000 \times 4096$이고, N개의 class일 때 SVM weight matrix는 $4096 \times N$이다.
이 분석은 R-CNN이 hasing과 같은 approximate technique에 의존하지 않고도 수천개의 object classes로 확장할 수 있음을 보여준다. 비록 class가 10만개일 지라도, matrix multiplication의 결과는 현대의 multi-core CPU에서 10초밖에 걸리지 않는다. 이 효율성은 단순히 region proposal과 shared feature의 결과는 아니다. UVA system에서는 고차원의 feature 때문에 2자리 수 더 느리며, 10만개의 linear predictor를 저장하는데 134GB의 메모리가 필요한 반면, 우리의 저차원 feature는 1.5GB만 필요하다.
R-CNN을 Dean등의 DPM과 hashing을 사용한 확장 가능한 detection 연구와 비교하는 것도 흥미롭다. 그들은 VOC 2007에서 1만개의 distractor classes를 도입했을 때, 이미지당 5분의 실행시간과 16%의 mAP를 기록하였다. 우리의 접근법으로는 1만개의 detector를 CPU에서 1분만에 실행할 수 있고, approximation이 사용되지 않기 때문에 mAP는 59%로 유지된다.
2.3 Training
Supervised Pre-training
우리는 대규모 보조 dataset (ILSVRC2012 classification)을 사용해 image-level의 annotation(bbox label은 없이)만으로 CNN을 먼저 학습시켰다. Pre-training은 Open source caffe CNN library를 사용해 수행되었다. 간략히 말해, 우리의 CNN은 Krizhevsky 등의 성능에 근접하며, ILSVRC2012 classification validation set에서 top-1 오류율이 2.2%p 더 높았다. 이 차이는 훈련 과정의 단순화로 인한 것이다.
Domain-specific fine-tuning
새로운 task(detection)과 새로운 domain(warped proposal window)에 CNN을 적응시키기 위해, 우리는 warped region proposal만을 사용하여 CNN parameter에 대해 SGD training을 계속 수행하였다. CNN의 ImageNet 특화된 1000-way 분류 계층을 임의로 초기화된 (N + 1)-way 분류 계층으로 바꾸는 것을 제외하고, CNN 아키텍처는 변경되지 않았다(N은 객체 클래스 수, 1은 배경을 위한 것이다). VOC에서는 N = 20이고, ILSVRC2013에서는 N = 200이다. 우리는 실제값 박스와 0.5 이상의 IoU를 가지는 모든 region proposal을 해당 박스 클래스의 양성으로 처리하고, 나머지는 음성으로 처리한다. 우리는 학습률 0.001(사전 학습 초기 학습률의 1/10)에서 SGD를 시작하여, 초기값을 훼손하지 않으면서 미세 조정이 진행되도록 한다. 각 SGD 반복에서, 우리는 모든 클래스에 걸쳐 32개의 양성 윈도우와 96개의 배경 윈도우를 균등하게 샘플링하여 크기 128의 미니 배치를 구성한다. 우리는 샘플링을 positive window로 편향시키는데, 이는 배경과 비교하여 positive window가 매우 희귀하기 때문이다.
Object category classifiers
자동차를 탐지하기 위한 이진 분류기를 훈련한다고 가정하자. 자동차를 밀접하게 둘러싼 이미지 영역이 positive example여야 한다는 것은 명확하다. 마찬가지로, 자동차와 관련 없는 배경 영역은 음성 예제여야 한다는 것도 명확하다. 하지만 자동차와 부분적으로 겹치는 영역을 어떻게 라벨링할지는 덜 명확하다. 우리는 IoU overlap threshold를 사용해 이 문제를 해결하며, 이 threshold 이하의 영역은 negative example로 정의한다. overlap threshold 0.3은 검증 세트에서 {0, 0.1, …, 0.5}에 대한 grid search로 선택되었다. 우리는 이 threshold를 신중하게 선택하는 것이 중요하다는 것을 발견했다. 0.5로 설정하는 것은 5%의 mAP를 감소시켰고 비슷하게 0으로 설정하는 것으 4%의 mAP를 감소시켰다. positive example들은 단순히 각각의 class에 대해 ground truth bbox로 정의된다.
특징이 추출되고 훈련 라벨이 적용되면, 우리는 클래스별로 하나의 linear SVM을 최적화한다. training data가 메모리에 비해 매우 크기 때문에, 우리는 hard negative mining방식을 채택했다. hard negative mining은 빠르게 수렴하고, 실제로는 모든 image를 한번만 통과시킨 후에 mAP의 증가를 멈춘다.
Appendix B에서 우리는 fine tuning과 SVM training에서 positive example과 negative example이 다르게 정의되는 이유에 대해 논의한다. 또한 fine-tuning된 CNN의 마지막 Softmax layer의 출력을 단순히 사용하기 보다 detection SVM을 사용한 것에 대한 논의도 진행한다.