2. Protocol Reverse Engineering(NetT)
Protocol reverse engineering (PRE) refers to the process of inferring the structure, semantics, and behavior of a communication protocol in the absence of official specifications or documentation
- fuzzing
- network traffic classification
Using Network Trace
Alignment Based Approach
메시지를 정렬하고 유사성 점수 계산 -> 점수를 기반으로 클러스터링 -> 메시지들의 공통점 분석 및 형식 도출
한계점: 메시지 내용의 다양성이 정렬의 품질을 저하시켜 분석하는데 문제 발생
Token Based Approach
1) Netzob
Needleman & Wunsch alignment
생물 정보학에서 단백질/뉴클레오티드 서열을 정렬하는데 사용되는 알고리즘이다.
두 개의 시퀀스를 최적의 방식으로 정렬하면서, 공통된 부분은 일치시키고, 차이점은 Gap(“-“)을 삽입하면서 정렬 Score가 최대가 되도록 만드는 전역 정렬 알고리즘맨 오른쪽 아래가 최종 스코어
UPGMA(Unweighted Pair Group Method with Arithmetic Mean)
가중치 없는 pair를 그룹하고 산술평균을 내는 계층적 클러스터링 알고리즘
어떤 메시지를 먼저 묶고, 어떤 순서로 클러스터를 합칠지 결정하는데 사용되는 알고리즘
2) Discoverer
Approach
- Initial Clustering
- “message pattern”을 기반으로 초기 cluster를 생성
- Recursive Clustering
- “message format”을 기반으로 초기 cluster를 split하고 merge하여 새로운 cluster생성
- Merge with Type based Sequence Alignment
- 위의 과정에서 cluster가 매우 많이 발생하기 때문에, “cluster format”을 활용해 cluster끼리 merging
3) NEMESYS
Problem
기존 방식들은 multiple message를 비교하여 format을 추론하였지만, intrinsic structure를 이용하지는 않음.
Background
3) NetPlier
목표: Keyword Field 유추(response or request or …)
Background
현존하는 Protocol Reverse Engineering은 실행 추적 기반(ExeT)방식과 네트워크 트레이스 기반 방식(NetT)으로 나눌 수 있다. 실행 추적 기반 방식은 어플리케이션에서 사용하는 입력 버퍼등을 직접 분석하여 역공학을 수행한다. 이에, 높은 정확도를 가지지만, 실행 파일들에 접근 할 수 있어야 한다는 한계가 있다. 이에 네트워크 패킷으로 부터 직접 protocol을 유추하는 방식을 사용할 수 있고, 이는 크게 다음과 같이 나뉜다.
- Alignment based method
- 정렬 알고리즘을 활용해 메시지들을 정렬하여 유사성 점수를 계산하고, 이를 기반으로 클러스터링한 후 분석하여 Format 유추
(단점: 메시지 내용이 다양하기 때문에 정렬의 품질이 저하됨)
- Token based method
- 메시지를 토큰화하여 변화를 줄인 후 정렬을 수행하고, 클러스터링하여 Format 유추
(단점: 토큰을 식별하기 위한 구분자를 필요로 하고, 토큰화가 Heuristics에 기반하기 때문에 부정확함)즉, 네트워크를 기반으로 PRE를 수행하기 위해서는 메시지의 클러스터링이 중요하다. 이때, 가장 문제가 되는 지점이 메시지 내용이 다양하기 때문에 정렬이 제대로 되지 않는다는 점이고, 이를 보완하기 위해 토큰화를 수행하는 방식이 등장하였다. 하지만, 여기서 토큰화 또한 Heuristic에 기반하기 때문에, 토큰이 잘못 분류되는 경우가 많아 문제가 발생한다.
Problem
- Alignemnt based clustering
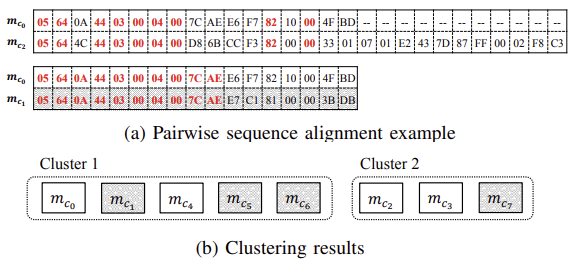
ⅰ) Alignment(Needleman & Wunsch): Pairwise 정렬이기 때문에 시간 복잡도가 높고, 정렬의 결과가 좋지 않다.
ⅱ) Clustering(UPGMA): Clustering의 결과가 threshold에 민감하게 달라지기 때문에, 프로토콜마다 최적의 Threshold가 달라진다.
※ $m_{c_0}, m_{c_2}$가 같은 종류의 패킷(요청==82)이고, $m_{c_0}, m_{c_1}$은 다른 종류의 패킷임에도 불구하고 니들먼 브니쉬 알고리즘의 잘못된 결과로 인해 $m_{c_0}, m_{c_1}$가 같은 Cluster로 판별되는 경우가 많다.
- Token based clustering
ⅰ) Binary Protocol에 명확한 구분자(경계)가 없음
ⅱ) Binary Token $\longleftrightarrow$ Text Token 구분이 정확하지 않음
$\quad$ (binary token이 길거나, text token이 짧은 경우 등)
ⅲ) Representation Token이 정확하지 않아 Over-Clustering이 발생
$\quad$ (같은 타입의 메시지라도, 특정 위치의 바이트 값이 달라 서로 다른 타입으로 분류하는 경우)※ Token based 방식은 ASCII 범위 내의 byte 값이면 Text라고 간주
이러한 내용들을 정리해보면 다음 두 문제가 핵심이 된다.
- 같은 타입의 메시지를 분류하기 위해 비슷한 값이나 패턴을 찾아 클러스터링 하는 방식을 사용한 것.
- 기존의 방법들은 한쪽(클라이언트/서버)에서 오는 메시지 데이터만 분석한 것.
Approach
(들어오는 프로토콜이 모두 같은 프로토콜이라고 가정)
Netplier에서는 기존의 결정론적인 방법을 사용하는 대신 Posterior distribution을 계산하여 활용하여 keyword 추출하는 방식을 제안한다.
- Preprocessing: application layer로 정형화
- time stamp, IP, port number, data(payload) 추출
- timestamp, IP, port number를 활용해 session number 라는 feature 부여
- Keyword field generation: clustering을 위한 keyword field의 후보 추출
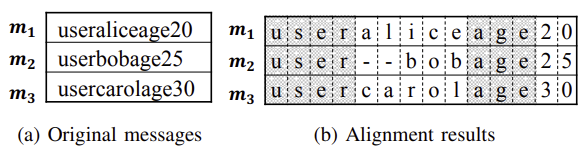
- 메시지 정렬(MSA, Multiple Sequence Alignment)
- 정렬된 결과에서 각 바이트를 Unit field로 취급(가장 Conservative한 결과)
- Unit field를 static한 부분과 dynamic한 부분 두 종류로 분류
- 연속된 같은 종류의 unit field를 조합해 Compound field 후보 생성(keyword가 꼭 단일 바이트일 필요는 없기 때문에)
- 이때, 클라이언트옹 필드 후보와 서버용 필드 후보를 따로 생성
※ 0 byte $<$ 후보군 크기제한 $<$ 10 byte
- Probabilistic Keyword Identification
4) PREUNN
문제점
- Approach
- 내 생각
- binary protocol을 다루지 않음
- real world setting에서의 영향을 다루지 않음
5) CNNPRE
- 문제점
- 입력이 unknown protocol의 경우 label이 없기 때문에, 비지도 학습(클러스터링)이 필요하지만 threshold에 따라 성능이 매우 바뀜
- 기존에는 정렬 방식을 주로 사용했는데, 이는 contextual information을 없앰
- pre proccessing에 domain knowlege 필요
- 아이디어
- 라벨이 없어 unknown data에 활용 불가 → transfer learning
- alignment → generate 2D image
- traffic length + traffic direction를 feature로 활용해 domain 지식 없이 추론
- Approach: PRE를 위한 Clustering 방식 제안
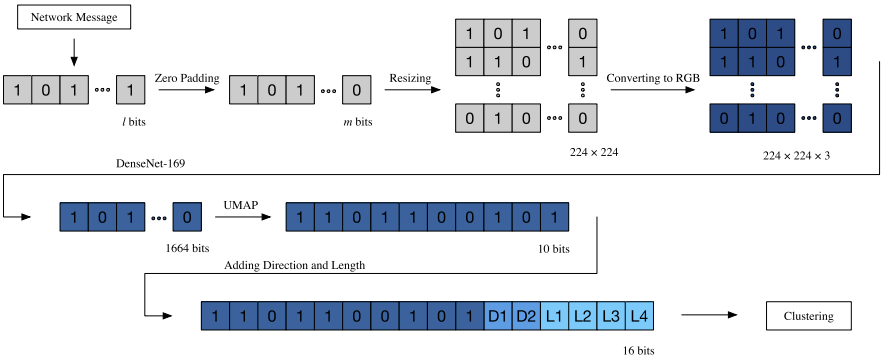
- Data Preprocessing
extract → calculate traffic characteristics(direct, length, …) → convert to image (resize 224 $\times$ 224 with padding) - Feature extraction & Dimension reduction
Densenet(for feature) & Uniform Manifold Approximation and Projection(for dim reduction) - Message type identification
Hierarchical Density-Based Spatial Clustering of Applications with Noise clustering algorithm
- Data Preprocessing
- 내 생각
- byte를 단순히 픽셀로 생각하기에는 무리가 있음 → 255를 넘어가는 값을 사용할 수도 있기 때문
6) ProsegDL
- 문제점
- delimiter-based(e.g. discoverer): binary protocol은 field 경계를 표현하는 symbol(delimiter)이 없고, 길이도 너무 짧음
- alignment-based: 정렬 과정이 noise에 취약함
- probability-based: 사전지식이 필요하고 이를 기반으로 파라미터를 조정해야 함
- 아이디어
- 패킷은 보통 header-payload 순으로 구성되고, header의 경우 보통 fixed length를 가짐
- 패킷을 쌓으면 이 fixed length 부분의 특징을 찾을 수 있음
(inter field features: 필드 간 구분되는 특징, intra field features: 필드 내부의 특징) 활용 - protocol은 대부분 상속에 의해서 구현 됨 (generalize 가능)
- Approach
- unet: intra field feature를 계산하는데 효과적인 architecture
- siamese network: inter field feature를 구분하는데 효과적인 architecture (필드간 유사도 계산 가능)
(backbone(lstm-fcn): feature extraction for sequence data에 유리함.) - cascade model: unet → siamese network
- 내 생각
- 실제로는 netplier와 같이 패킷들을 클러스터링하여 분해하는 과정이 선행됨. 따라서, 이 클러스터링 결과에 매우 의존하게 됨.
- space packet/message가 섞여서 길이가 다양해져 header가 고정되지 않는 경우, 패킷을 쌓는 방식으로는 적용할 수 없다.
(패턴이 매번 달라질 것이기 때문) - 패킷을 쌓는 방식도, message가 섞여서 다양한 protocol을 한번에 인식하는 경우 적용하기 힘들 것 같다.
(마찬가지로 패턴을 찾기 힘들 것임) - binary pattern(e.g. header)과 text pattern(e.g. payload)가 명확할 때만 사용가능할 것 같다.
만약 둘 중 하나만 사용하면 성능이 많이 떨어질 것 같다.(inter field feature계산 불가)
8) (2023 NDSS) BinaryInferno
Idea
Engineer들은 보통 표준 encoding 방식을 반복해서 사용한다.(e.g. IEEE 754 부동소수점 수, Timestamp, TLV/LV Encoding) 이러한 점을 활용하기 위해 다음 두가지 단서를 활용할 수 있다.
- 단일 메시지 내부의 정보: 특정 위치의 데이터가 정수/부동소수점인지.
- 여러 메시지들 사이의 정보: 여러 메시지 간, 수집된 단서들 간의 상관관계 분석
이를 위해서 메시지 type을 식별하는 detector들을 만들어 이를 활용해보자.
Approach
다음 Detector를 모든 위치에 대해 수행함으로써 전체 메시지에 대한 Description을 생성할 수 있다.
- Atomic Detector: 기초 field를 식별하는 탐지기
- Float Detector
IEEE 754 형식은 [부호(1 bit), 지수(8 bit), 가수(32 bit)] 형태이다. 이때, 보통 실제 데이터에서는 여러 실수들이 동일한 지수값을 공유하고, 가수 부분만 다르다. 또한, 여러 메시지들에 대한 bit frequency를 보면, 지수 영역에 있는 1 bit 개수 빈도가 가수 영역에 있는 1 bit 빈도보다 더 많아지는 현상이 있다. (히스토그램을 그리면 L자 모양의 패턴 발생, unsigned int와 같은 데이터에서는 나타나지 않음)- Timestamp Detector
패킷 캡쳐 시작/종료 시간을 기반으로, 해당 슬라이스를 timestamp 형식으로 해석했을 때 범위 내에 있다면 timestamp 형식으로 추론(NTP & UNIX epoch timestamp formats)- Length Detector
여러 메시지들 중에서 특정 위치의 byte값과 전체 길이를 비교하여 결정할 수 있다. (한 cluster에서 2번 byte의 값이 [9, 10, 13]이고, 전체 길이가 [13, 14, 17] 이면 $L_i -x_i$의 값이 일정하므로 length field로 볼 수 있다.)
- Field Boundary Detector: 엔트로피 변화를 이용한 필드 경계 탐지기
- 인접한 1byte slice간 shannon entropy 차이가 큰 곳을 경계로 추정
- Pattern Based Detector: 직렬화 패턴(TLV, LV)을 바탕으로 가변 길이 필드 추론
- 가변 길이 필드에서 사용하는 주요 패턴은 LV(길이+값, e.g.
0x03 AABBCC)과 TLV(타입+길이+값, e.g.0x01 0x03 AABBCC)이 있다. 이러한 패턴을 탐지하기 위해 iterative deepening DFS를 사용해 패턴 후보들을 찾는다.(깊이1(LV) → 깊이2(TLV) → 깊이3(QTLV) → …, Q는 반복 횟수)이때 가장 중요한 것은 여러 Detector가 동일 byte에 대해 서로 다른 주장을 할 경우 이를 통합하는 방법을 설계하는 것이다.
이를 해결하기 위해 DAG를 사용해 Conflict가 없는 field 조합을 찾는 문제로 전환시킬 수 있다.
이러한 통합 알고리즘은 개별 Detector의 오류에 대해 강건한 system을 설계할 수 있게 만든다.