3. Planning
Planning
자율주행의 구성기술은 다음과 같다.
- 인지: 센서로 주변인식
- 판단: 경로생성 + 주행상황 판단
- 제어: 경로추종
여기서는 판단기술이 하는 역할에 대해 알아보자
1. 입력
1) 센서
| 카메라 | 라이다 | 레이더 | |
|---|---|---|---|
| 장점 | ⅰ. 정보의 양이 많음 ⅱ. 원거리 물체를 인식 가능 | ⅰ. 거리정보에 강함 ⅱ. 날씨 변화에 강함 | ⅰ. 속도탐지에 유리함 ⅱ. 원거리 물체를 인식할 수 있음 |
| 단점 | ⅰ. 거리정보에 약함 ⅱ. 날씨 변화에 약함 | ⅰ. 정보의 양이 적음 ⅱ. 센싱거리에 한계가 있음 | ⅰ. 해상도가 낮음 ⅱ. 횡방향 정확도가 낮음 ⅲ. 비금속 물체 탐지에 취약함 |
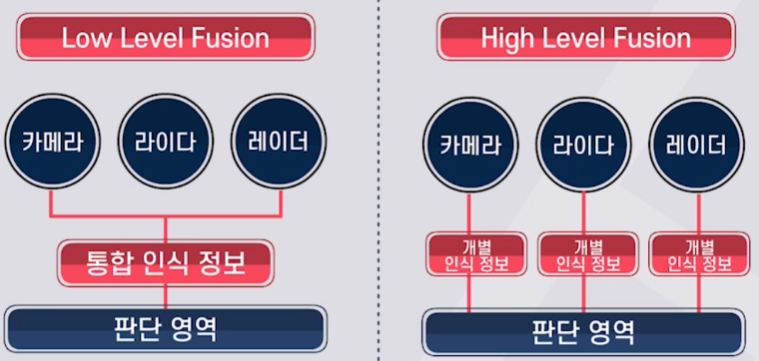
센서정보 활용 방법
센서퓨전 (Low Level Fusion) 멀티센서관점 (High Level Fusion) 정의 카메라, 라이다, 레이더의
통합인식정보를 전달받아 판단하는 것카메라, 라이다, 레이더의
개별 인식정보를 전달받아 판단하는 것특징 판단부분에서 고려할 요소들이 적지만
그만큼 인식정보가 매우 정확해야 함센서별 신뢰도 우선순위를 상황별로
다르게 할 수 있음 (ex. 현재 날씨)
2) 통신(도로 인프라)
| V2I | V2X |
|---|---|
| 좁은의미의 도로 인프라 | 넓은 의미의 도로 인프라 |
| V2I (Vehicle to Infrastructure) | V2I (Vehicle to Infrastructure) V2V (Vehicle to Vehicle) V2P (Vehicle to Pedestrian) V2N (Vehicle to Network) V2C (Vehicle to Cloud) |
현재 센서기반 자율주행은 큰 발전을 이루었고
앞으로는 인프라와의 통신을 활용하는 것이 큰 관건이 될 것이라고 한다.
정보의 중복
자율주행 자동차는 센서에서도 정보를 받는다.
즉, 통신틀 통해서 정보를 받을 경우 정보의 중복이 발생할 수 있는데, 이 정보는 안전성 향상을 위해 반드시 필요한 정보이다.정보의 업데이트
차량은 HD-MAP이라고 하는 고정밀 지도를 통해 자신의 정확한 위치를 추측하고 경로를 계획한다.
이때, 도로의 정보는 꾸준히 바뀌기 때문에 이 HD-MAP을 항상 최신상태로 유지할 필요가 있다.즉, 수많은 차들이 운행중에 얻은 정보에 대해 V2C를 통해 Cloud를 업데이트 하고
운행중인 차량들은 이 정보를 받아 자신의 HD-MAP을 업데이트 받을 필요가 있다.
2. 주행상황 판단
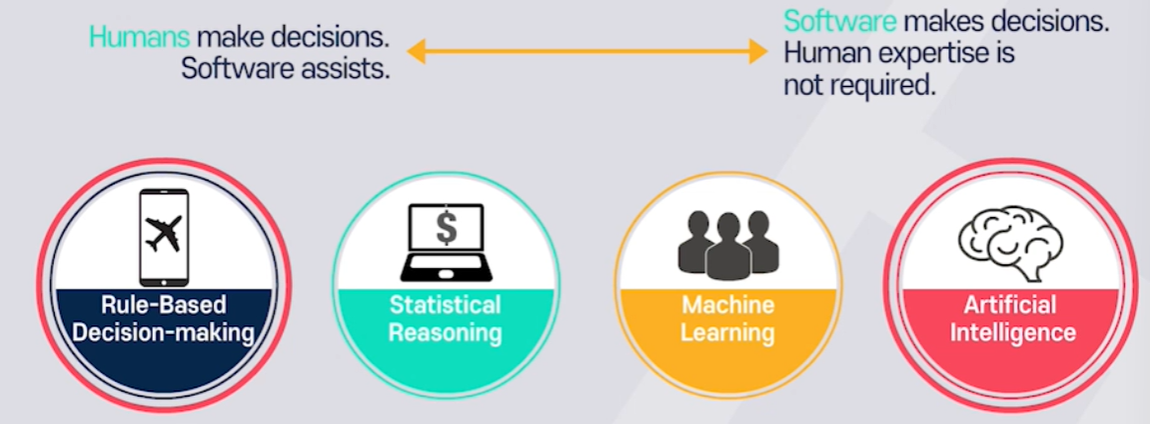
1) 판단 종류
Rule Based 방법 AI Based 방법 구성 사용 상황 간단한 경우 (크루즈 모드) 복잡한 경우 (교차로 상황) 특징 인식 정보(센서+인프라)의 개수가 적음 인식 정보(센서+인프라)의 개수가 많음 장점 정확한 성능 예측 가능 융통성 $\uparrow$
(다양한 주행환경 가능)단점 융통성 $\downarrow$
(다양한 주행환경 불가)ⅰ. 특정 기준에 대한 잣대가 없음
ⅱ. 고장판단 및 오류수정이 어려움
ⅲ. 상황별 정보의 우선순위 레벨의
$\quad$직접적 설정이 불가함예시 ⅰ. 차로유지판단
$\quad\rightarrow$ 양 차선의 중앙을 찾아 경로 생성
ⅱ. 차로변경판단
$\quad\rightarrow$ 양 차로의 중앙값으로 경로 후보들 생성
$\quad\rightarrow$ 주변차량과 거리, 속도 확보 후 차선변경
ⅲ. 교차로 상황 판단
$\quad \rightarrow$ 정보 인식 및 충돌 회피 규칙 설정
$\quad\rightarrow$ 정보의 우선순위 설정이 중요ⅰ. 센서 정보(자차/주변차량의 위치/속도 등)
ⅱ. 제어 신호(조향각, 가/감속, 판단결과 등)
를 학습시켜 새로운 상황에 적합한 판단 수행
- 유의점
- 상황별로 신뢰할 센서, 인프라의 우선순위가 있어야 함
- 서로 다른 센서/인프라가 같은 대상에 대한 인식정보를 제공할 때
신뢰도 분배에 대한 결정이 필요함이때, AI Based는 상황별로 정보의 우선순위를 직접 결정하기 어렵기 때문에
교차로 상황에 대한 전체적인 학습보다는 일부 상황에 대한 기능을 분리학습하는 방법이 필요하다.즉, 두가지 방법을 융합하는 방식이 활발하게 연구되고 있다.
2) 상황별 판단
상황 사용센서 특징 LKA모드/
크루즈 모드
(SCC, ACC, ASCC)ⅰ. 카메라
ⅱ. 레이더ⅰ. 차간거리 유지 기능 + 차선유지 보조기능(LKA)
$\quad$- 카메라: 차로정보 인식
$\quad$- 레이더: 선행차량정보 인식(거리, 속도 등)
$\quad$ ※횡방향 오차와 헤딩각 오차를 모두 고려해야 함
ⅱ. 상황별 행동
$\quad$ - 선행차량이 없을 때: 설정된 속도로 가/감속 후 주행
$\quad$ - 선행차량이 있을 때: 설정된 차간거리를 유지하며 주행차로변경/
추월ⅰ. 카메라
ⅱ. 라이다
ⅲ. 레이더ⅰ. 전/후방 차량의 거리 및 속도 측정
$\quad$ - 목표 차선에 대해 확인 필요
$\quad$ - 360도 센싱이 중요
ⅱ. 진입가능 여부 판단
$\quad$ - 가능할 경우: 진입시 필요속도 계산
$\quad$ - 불가능할 경우: 대기/2연속 변경에 대한 판단
ⅲ. 추월시 차로변경 N회 시행교차로
(좌/우회전)ⅰ. 카메라
ⅱ. 라이다
ⅲ. 레이더ⅰ. 센싱해야할 정보가 많음 (우선순위 설정 필요)
$\quad$ - 카메라기반 신호등 인식
$\quad$ - 상대 차량의 의도 파악
$\quad$ - 동적 객체들에 대한 충돌예측
ⅱ. 중간영역에는 차로가 없음
$\quad$ - 차로 인식 기반의 의존도 $\downarrow$
$\quad$ - 가상의 경로 생성
$\quad$ - 주변차량과의 협력 주행 필요
(V2X가 가장 잘 활용될 수 있고 가장 필요한 상황임)돌발 상황
(임시공사, 사고)ⅰ. 카메라
ⅱ. 라이다
ⅲ. 레이더돌발상황 회피 및 연속주행이 목표
ⅰ. Rule based판단
$\quad$- 예외처리로 규정된 경우를 제외한 모든 상황을 처리
$\quad$- 모든 경우에 대해 대응하는데 한계 존재
ⅱ. AI Based
$\quad$- Scene Classification, Scene Understanding
$\quad$- 주행가능공간 판단날씨
(눈비, 안개)ⅰ. 레인 센서
$\quad\rightarrow$ 눈비의 양 파악
ⅱ. 타이어 슬립 추정
$\quad \rightarrow$ 노면상태 파악
ⅲ. 딥러닝(장면분류)
$\quad\rightarrow$ 날씨 추정각각의 날씨 및 도로 상태에 대한
주행 기준 마련이 필요함안전을 위한 판단
1. V2X정보 기반 판단 2. Fail Safe 판단 중요성 안전성을 위한 정보의 중복성 관점에서
반드시 필요어떤 부분에 기능적인 Fail이 발생하면
자체적인 안정장치가 동작해야 함특징 ⅰ. 센서기반인식만 사용
$\quad$- 정확성 부족
ⅱ. V2X통신기반인식
$\quad$ - 해킹 및 인프라의 항상성 문제Fail Safe 단계별 특징
ⅰ. Fail Passive
$\quad$ - 곧바로 운행 중지
ⅱ. Fail Active
$\quad$ - 경보를 울리고 짧은시간 동안만 운행
ⅲ. Fail Operational
$\quad$ - 보수가 될때까지 기능 유지 가능
$\Rightarrow$ 부품 고장을 대비해 장비를 여러개 사용
$\Rightarrow$ 소프트웨어적으로 다른센서가 고장부품을 대체
3. 경로 생성
1) 경로 생성 알고리즘
경로계획기술: 출발지점부터 목적 지점까지 경로를 생성하는 과정 주변환경 인식기술 자차위치 인식기술 필요
경로계획 종류
전역 경로 계획 지역 경로 계획 특징 이미 풀린 기술 안전성과 효율성을 동시에 생각해야 함 예시 $A^*$ 알고리즘 RRT 알고리즘
RRT* 알고리즘
$A^*$ 알고리즘 RRT 알고리즘 그림 동작 과정
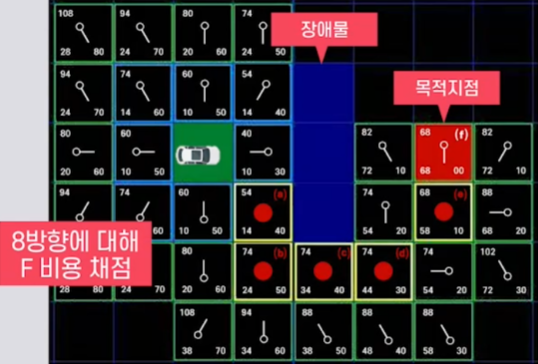
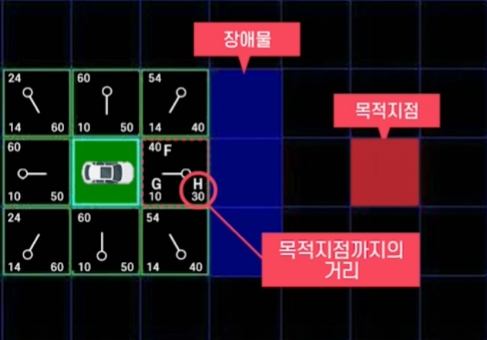
ⅰ. 현실 세계를 2D Grid로 Modeling
ⅱ. 8방향에 대해 Cost를 고려해 다음 위치 결정
$\quad Cost=G$(시작점-현재 실제비용)
$\quad\quad\quad\quad\;$ + $H$(현재-목적지 예상비용)
ⅲ. 위 과정을 계속적으로 반복 동작
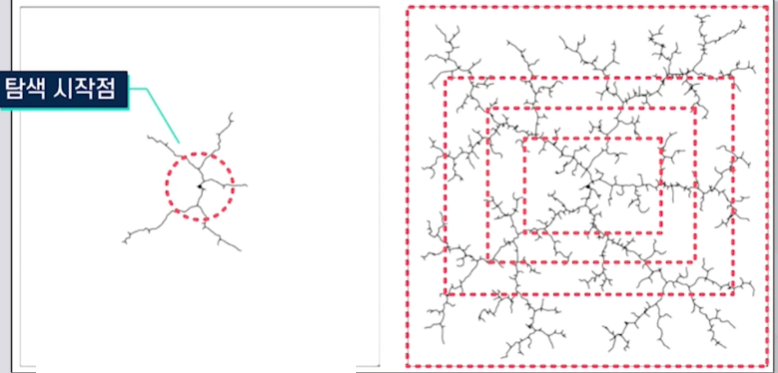
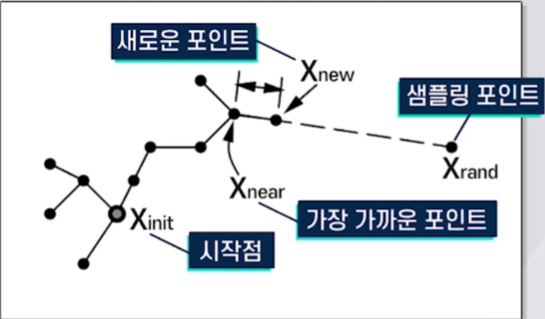
ⅰ. 근접한 Point들을 Sampling을 통해 생성
ⅱ. 현재 Graph에서 샘플링 포인트와
$\quad$ 가장 가까운 Point 선택
ⅲ. 가장 가까운 포인트와 Sampling Point사이에
$\quad$ 새로운 포인트 생성
ⅳ. 위 과정을 목적지점까지 반복수행
ⅴ. 여러 경로 중 최적의 경로 선택특징 격자단위의 크기에 따라 성능이 결정됨 장애물 부분에는 샘플링 포인트 생성 X
샘플링 포인트의 개수에 따라 성능이 결정됨
경로의 최적성이 보장되지는 않음RRT에서 비용함수를 도입한 알고리즘이 RRT알고리즘이다.
이를 통해 RRT는 RRT에 비해 최적성을 개선하였다.
2) 강화 학습
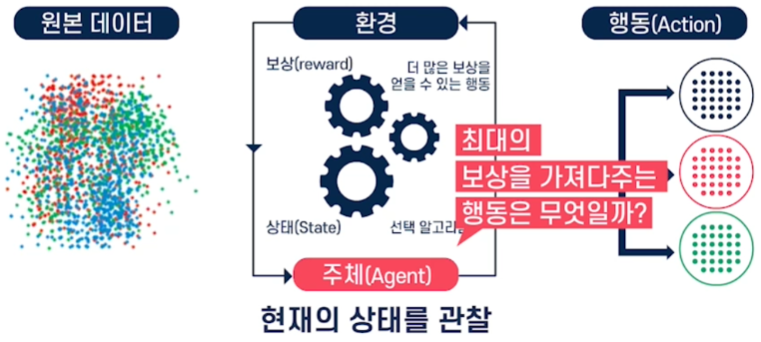
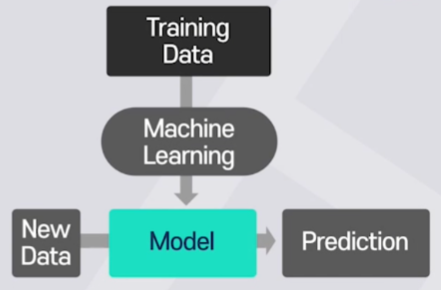
강화학습이란 보상 시스템으로 모델을 학습시키는 것을 말한다.
주행센서의 입력 데이터와 그에 따른 판단결과가 다양할수록 강화학습 모델의 성능이 향상된다.
(ex. 차선유지 시나리오)강화학습은 다음 3가지의 구성요소로 이루어져 있다.
Policy
Agent가 주어진 State에서 어떤 Action을 취할지 결정하는 방법을 의미한다.
- Deterministic Policy: 정해진 방법으로 Action을 취하는 것
- Stochastic Policy: Action에 확률을 부여해서 결정하는 것
Policy Based: Policy가 완벽하다면 Value Function이 꼭 필요하지 않게 됨
- ex. Policy Gradient
Value Function
State와 Action에 대해 어느정도의 Reward를 받을 수 있을지 예측하는 함수
즉, Value Function이 완벽하다면 최적의 Policy를 선택할 수 있게된다.Value Function Based: 완벽한 Value Function으로 설계하는 방식
- ex. DQN
Model
환경의 다음 State와 Reward가 어떻게 될지에 대한 Agent의 예상
- State Model
- Reward Model
3) 모방 학습
딥러닝 모델이 사람과 비슷하게 운전하도록 학습시키는 것