3. Perception(2)
자율주행 통합 인지 시스템
1. 인지 심화
| 카메라 | 레이더 | 라이다 | |
|---|---|---|---|
| 장점 | 높은 해상도 저렴한 가격 | 높은 정확도 저렴한 가격 강인한 성능 속도정보 획득가능 | 높은 정확도(먼 거리) 강인한 성능 |
| 단점 | 환경변화에 취약 높은 계산량 낮은 정확도(속도 및 거리) | 높은 오탐률(클러터 현상) 횡방향에서 낮은 정확도 BEV에서만 표현되는 물체검출 결과 | 비싼 가격 습기에 취약 해상도가 낮음 |
1) 센서융합
| 구분 방식 | 융합 위치 | 센서 |
|---|---|---|
| 종류 | ⅰ. 초기융합 ⅱ. 후기융합 ⅲ. 중기융합 | ⅰ. 카메라 + 라이다 ⅱ. 카메라 + 레이더 ⅲ. 카메라 + 레이더 + 라이다 |
보다 정확한 인지 결과를 위해서는 센서융합이 필요하다.
하지만 카메라(2차원, 카메라 좌표계), 레이더(3차원), 라이다(3차원)는 모두 사용하는 좌표계가 다르기 때문에
이를 캘리브레이션해야 하기 때문에 어려운 과정이 수반된다.1. 센서 융합 위치
융합 방법 장점 단점 초기융합 센서의 원시데이터 정보를 융합합하는 방식 낮은 계산량 카메라+라이다처럼 데이터의 분포가 완전히 다를 경우 성능이 낮아진다. 후기융합 센서별로 인지결과를 내고 이를 마지막에 융합하는 방식 센서별 오작동 분석 가능 높은 계산량 중기융합 센서별로 인지결과(특징값)를 내고 융합한 후,
이 결과를 다시 인지에 사용고해상도를 갖는 센서에서 주로 사용 - (딥러닝에서는 주로 중기융합을 활용한다.)
특징값 추출 방법은 다음과 같다
- 카메라 영상: CNN
- 라이다 포인트 클라우드: 3차원 복셀구조 인코딩
2. 융합 센서 종류
융합방법 paper 카메라 + 라이다 1. 라이다의 해상도가 높지 않은 경우
$\rightarrow$ 카메라 중심의 융합기술
ⅰ. 카메라 영상에 CNN적용
ⅱ. 물체에 대한 2차원 박스 검출
ⅲ. 라이다의 프러스텀에 존재하는 포인트 추출
ⅳ. 포인트넷 등의 딥러닝 모델을 적용해 3차원 검출
2. 라이다의 해상도가 높은 경우
$\rightarrow$ 라이다 중심의 융합기술프러스텀 포인트넷
AVOD
MMF
Cont-Fuse
3D-CVF카메라 + 레이더 $\because$ 카메라: 인식결과 $\uparrow$ , 위치측정능력: $\downarrow$
$\because$ 레이더: 인식결과 $\downarrow$(오탐률 때문) , 위치측정능력: $\uparrow$
$\rightarrow$ 상호 보완이 됨카메라 + 레이더 + 라이다 많은 계산량이 필요하기 때문에
그만큼 하드웨어능력과 알고리즘의 구현이 필요(프러스텀: 카메라의 2차원 박스에 대응하는 라이다의 3차원 포인트 부분)
2) 추적+검출
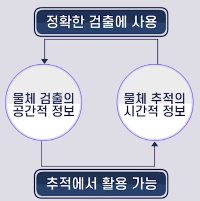
기존에는 검출, 추적기술이 따로 설계되고 연구되어왔다.
이때, 각 기술은 다음과 같이 1가지 정보만 활용하는 것을 알 수 있다.
- 검출: 센서의 공간적 정보만을 활용
- 추적: 센서의 시간적 정보만을 활용
즉, 검출과 추적기술시 각각의 정보를 서로 교환하며 최적화될 필요가 있다.
검출
일반적으로 검출은 프레임 단위로 발생한다.
이 때문에 물체의 음영에 의한 왜곡(Blurring 등)이 발생할 수 있다.이를 해결하기 위해서는 동영상을 한번에 처리할 필요가 있다.
즉, RNN기반 모델을 통해 특징값을 추출하고 이를 검출과정에서 활용할 필요가 있다.
추적
마찬가지로 추적에서도 공간적인 정보를 활용할 필요가 있다.
즉, 각 프레임,(다중)센서 별로 CNN으로 특징값을 추출한 결과로 다시 추적 작업, 그 중 “연결”부분에서 재사용할 필요가 있다.
3) 거리추정
방법 설명 스테레오 비전 1. 두 카메라를 보정해 좌표계 확립
2. 스테레오 정합을 통해 두 영상의 대응점을 찾아냄
3. 두 대응점 사이의 위치차이(Disparity)를 계산
4. 거리추정
$\rightarrow$단점: 카메라의 보정오차에 민감함스테레오 비전 + 딥러닝 1. 카메라영상 취득
2. CNN을 적용해 Disparity지도 생성
3. 이를 실제 Disparity와 비교해 학습
$\rightarrow$보정오차에 강인한 성능을 가짐단일카메라 + 딥러닝 방법1: 대규모 영상으로부터 물체 크기 등의
사전지식을 학습해 추정
방법2: 단일 영상으로부터 반대편 영상을 생성해
스테레오 카메라를 만들어 거리추정(딥러닝 방법의 경우 RGB-D 카메라 센서를 통해 Ground Truth를 얻을 수 있다.)
2. 측위
1) 지도
자율주행을 위해서는 cm단위(최대 20cm)의 정확도를 갖는 고정밀 지도가 필요하다.
이 고정밀 지도는 MMS(Mobile Mapping System)을 이용해 사전에 제작되고,
자동차는 이를 이용해 자신의 현재 위치를 알 수 있다.
현재 지도를 만드는 기술에 대한 표준화는 활발히 논의되고 있는 상태이다.
지형지도
센서데이터를 이용해 주변 지형을 3차원 형태로 구성한 지도이다.
시맨틱 지도
측위와 관련된 특정 지형(교통정보, 랜드마크)등을 임베딩하여 고정밀 지도위에 표현해 놓은 지도이다.
LDM(Local Dynamic Map)
자율주행, 인프라, 엣지의 센서에서 얻은 동적 객체들의 위치/상태 정보들을 고정밀 지도에 융합시켜 활용하는 방법을 말한다.
$\rightarrow$ V2X와 같은 기술을 활용해 협력주행에도 이용이 가능하다.
$\rightarrow$ LDM에서 얻은 정보는 고정밀 지도 업데이트에도 사용 가능하다.
2) 측위기술
측위기술이란? 고정밀 지도위에서 자신의 위치를 알아내는 것을 말한다
기존의 측위기술
기술 설명 정밀도 단점 GPS 위성을 통해 위치를 알아내는 방식으로
전파수신상황에 따라 위치 정밀도가 좌우됨m단위 오차가 크다
음영지역 존재RTK
(Real Time Kinematic)위성을 사용해 정밀한 위치를 확보한 기준점의
반송파 오차를 보정치로 적용하는 기술cm단위 고가의 장비가격
음영지역 존재GPS IMU등 관성 센서 정보를 활용하는 방식 - 시간에 따라 오차 누적 기존의 측위 기술은 이상적인 상황을 가정해서 자신의 위치를 추정하기 때문에 측위의 정확도가 매우 떨어진다.
Odometry
차량이 이전 상태에서부터 얼마나 움직였는지 알아내는 것을 말한다.
Visual Odometry LiDAR Odometry 정의 카메라 영상으로부터 카메라의 움직임을 추적해
차량의 위치를 추적하는 방법포인트 클라우드의 움직임을 추적해
차량의 위치를 추적하는 방법방법 1. 카메라 영상에 CNN을 적용해 특징지도 추출
2. RNN을 사용해 영상의 시간적 움직임 추적
$\rightarrow$ 카메라의 성능에 따라 정확도가 좌우됨정합기술을 사용해 움직임 추적
(정합: Point Cloud간의 대응점을 찾는 기술)
$\rightarrow$ 정확한 정합기술이 필요예시 Deep VO LoNET 통합 Odometry 기술도 있는데, 이것은 관성항법장치와 카메라/라이더 센서 데이터를 종합해서 Odometry를 측정하는 기술이다.
맵매칭
센서 데이터와 지도정보를 매칭하여 내가 현재 어디위치에 있는지 파악하는 기술이다.
Descriptor Matching 기술
ⅰ. 센서 데이터로부터 로컬특징점을 검출한다.
ⅱ. 로컬 특징점과 지도에 임베딩된 Descriptor를 비교해 차량의 위치를 추정한다.단점
ⅰ. 센서오차나 환경변화에 큰 영향을 받는다.
$\rightarrow$ 딥러닝을 사용하면 새로운 환경에 대해서도 예측할 수 있는 모델을 만들 수 있다.
3) SLAM
지도생성과 측위를 동시에 하는 기술
자율주행에서는 Cm단위의 위치인식 기술이 필요하다.
이를 위해 기존의 센서데이터와 Odometry 정보를 합쳐 SLAM을 수행한다.
마지막으로 이를 최적화하여 정밀지도를 제작한다.
LiDAR SLAM Camera SLAM 방법 Scan Matching(=Map Matching)
정밀지도 정보 + LiDAR Scan데이터를 실시간 비교Tracking + Local Mapping + Loop Closing 종류 ⅰ. ICP 방식(Iterative Closest Point)
$\quad$ Point Cloud점들을 그대로 매칭에 활용
$\quad \rightarrow$ Rotational Error가 적음
ⅱ. NDT 방식(Normal Distribution Transform)
$\quad \rightarrow$ Initial Pose를 찾는데 빠름ⅰ. Feature Based 방식(ex. ORB SLAM)
$\quad$ Feauter들과 Map Point와의 Mathcing을 통한 Localization
$\quad \rightarrow$ 장점: 복잡함, 특징정보가 없는 지역에서 성능 하락
ⅱ. Direct 방식 (ex. LSD SLAM)
$\quad$ 간단한 특징 영역의 Filtering 및 pixel정보 사용
$\quad \rightarrow$ 장점: 간단함
3. 플렛폼
1) 데이터
데이터에 따라 머신러닝, 딥러닝의 성능이 결정되므로 많은 데이터의 확보가 중요하다.
또 이때 유의해야할 점은 일회성의 데이터로는 자율주행이 불가능하다는 것이다.
즉, 새로운 데이터가 계속해서 학습되어야 한다.
이를 위해서 데이터 취득, 라벨링, 학습, 검증, 적용(탑재)를 수행하는 시스템 플랫폼이 필요하다.
데이터 취득
- 전용차량을 통한 수집
- 자율주행차에서 수집된 데이터를 클라우드로 수집
- 인프라, 엣지등의 센서에서 데이터수집
데이터 검증 및 라벨링
- 능동학습
: 불확실성이 큰 데이터만 라벨링하여 적은수의 데이터로 학습 성능을 극대화 시키는 전략검증
- 시뮬레이션을 통한 테스트
- 섀도우모드
: 자율주행차에 학습 모델을 탑재하여, 실제 작동되지는 않고 실제 상황에서는 어떻게 동작할지 테스트해보는 것탑재
- 지속적인 관리 및 업데이트가 필요
- OTA(Over The Air)라고하는 무선 업데이트 기술
2) 하드웨어 가속기
GEMM(General Matrix and Multiply Engine)
: 딥러닝에서 행렬의 곱을 수행하는 가속기SRAM
: 딥러닝 모델의 가중치, 활성화 값을 저장하는 곳DRAM
: 결과물이나 입력 데이터를 저장하는 곳컨트롤러
: 제어나 통신을 위한 명령을 수행하는 곳InterConnect/Fabric
: 유닛간의 데이터를 교환해야 하기 위한 연결 로직경량화/ 모델 압축 방법
- 노드 프루닝
- 채널 프루닝
- Depthwise Separable Convolution
3) 차량 네트워크
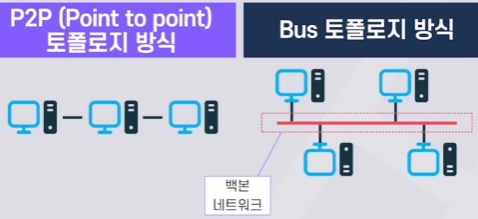
P2P: 속도 및 시간지연 우수
BUS: 확장성 및 비용이 우수
(Bus 토폴로지: 공용(백본)네트워크가 있어 데이터를 주고받는 것)
종류 토폴로지 전송속도 특징 CAN Bus 토폴로지 ~1Mbps 현재 가장 대중적인 차량 네트워크
(고속의 데이터 전송이 불가능)FlexRay Bus 토폴로지 ~10Mbps 고속데이터 전송을 위한 방식 MOST Bus 토폴로지 ~24Mbps 멀티미디어 전송 전용 방식 Twisted Pair 이더넷 Bus 토폴로지
—————
P2P 토폴로지~10Mbps
—————
100Mbps~10Gbps집에서 유선 통신을 위해 사용하는 방식 Serdes P2P 토폴로지 ~16Gbps ⅰ. 링크 기반의 고속차량 통신 기술
ⅱ. 고해상도 데이터 전송을 위해 사용
(ex. 카메라)