5. Object Detection(Two-Stage)
Object Detection
1. BackGround
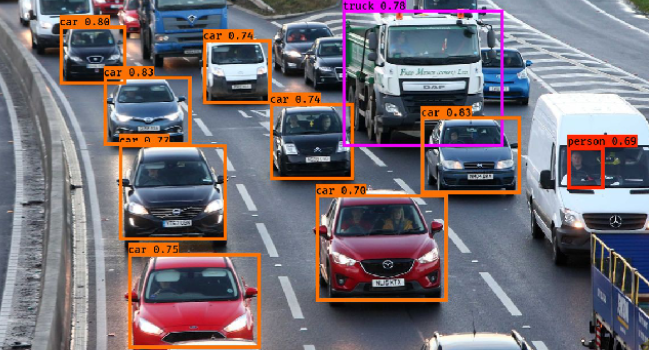
1) 이미지 분류모델의 종류

Classification Object Detection Segmentation 정의 이미지를 판단하는 모델 Bounding Box를 통해
객체를 탐지하는 모델Classification을
Pixel단위로 수행하는 모델Output class번호 bbox, class segmentation map 종류 1. One-Stage Detector
2. Two-Stage Detector1. Semantic Segmentation
(Class단위 분류)
2. Instance Segmentation
(객체단위 Class분류)
3. Panoptic Segmentation
(Semantic + Instance)

2) 용어
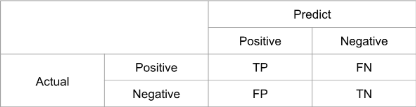
Confusion Matrix
모델이 얼마나 잘 예측했는지 평가하기 위해 각 Case별로 나누어 표시하는 것
- $Precision=\frac{TP}{TP+FP}$
- 모델이 True라고 분류한 모델중 실제 True인 것의 비율
- $Recall=\frac{TP}{TP+FN}$
- 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
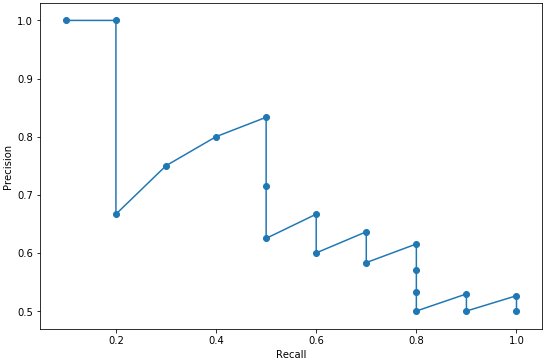
PR Curve
매 예측에 대해 Precision과 Recall의 변화를 계산하여 그래프를 그리는 것
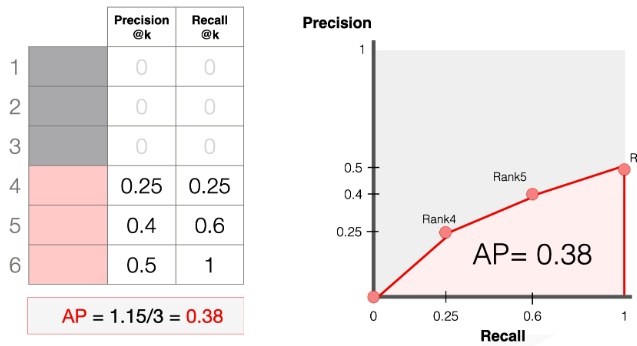
AP(Average Precision)
하나의 Class에 대해 PR Curve를 구했을 때, 이 PR Curve에서의 아래면적의 크기
- mAP(mean Average Precision)
- 모든 Class에 대해 AP를 구했을 때 이 AP의 평균
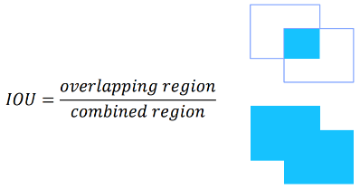
IOU(Intersection Over Union)
Classification은 맞고 틀리고에 대해서 명확히 판별할 수 있었지만, Detection에서는 이것을 단정지을 수 없다.
이를 위해 IOU를 사용하는데,
예를들어 “IOU 60”의 경우 전체 면적중에서 Bounding Box가 겹치는 부분이 60%이상인 것들만 정답으로 취급한다.
(마찬가지로mAP 60은IOU 60을 기준으로 mAP를 측정한 것이다.)
3) Selective Search

ROI(Region of Interest)를 추출하는 전통적인 방법으로 다음과 같은 과정을 통해 물체가 있을법한 영역의 후보군을 추출하게 된다.
- 이미지의 색갈, 질감, 모양등을 활용해 무수히 많은 작은 영역으로 나눈다.
- 이 영역들에서 겹치는 부분이 많은 영역들을 점차 통합해 나간다.
Selective Search는 정해진 알고리즘이 있어 작동원리를 이해하기 쉽다는 장점이 있었지만, 현재는 이렇게 정해져 있다는 점이 오히려 학습이 불가능하다는 단점으로 바뀌어 잘 사용되지 않는다고 한다.
(End-to-End 모델이 될 수 없다.)
4) NMS(Non-Maximum Suppression)
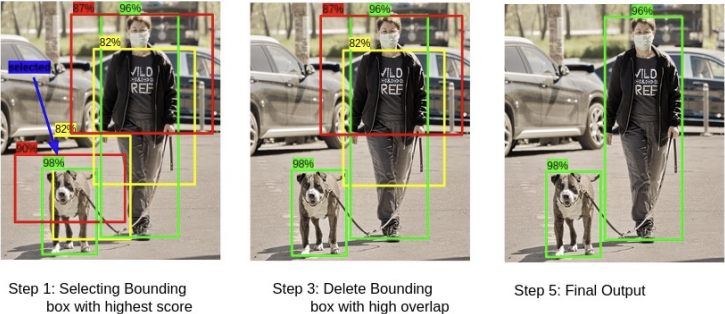
RPN의 결과로써 나온 ROI중에는 유사한 객체를 표현하는 ROI들이 여럿 존재하게 된다.
이를 막기 위해 Class Score를 기준으로 정렬한 후에, 중복된 영역이 많은 순서대로 ROI후보군을 삭제해 가면서 적절한 것을 Proposal 영역을 최소한으로 골라주는 알고리즘을 말한다.
(자세한 내용)
5) One-Stage & Two-Stage
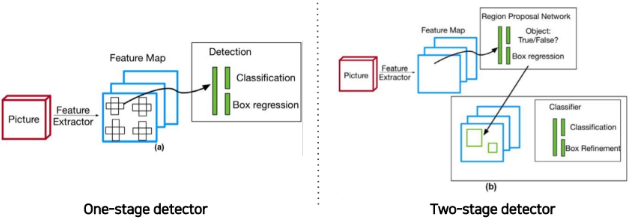
Detector One-Stage Two-Stage 탐지과정 1. 이미지를 grid로 나눔
2. 각 grid에서 물체위치 추정
3. 동시에 각 grid별 Classification1. Region Proposal로 물체위치 추정
2. 이 위치 안의 물체를 Classification특징 실시간 탐지 가능 정확한 탐지 가능 종류 YOLO RCNN Family
SPP Net
2. Two-Stage Detection Model
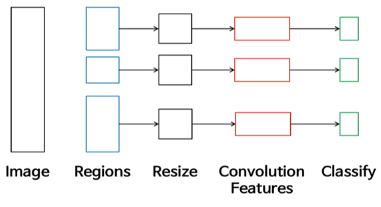
1) R-CNN
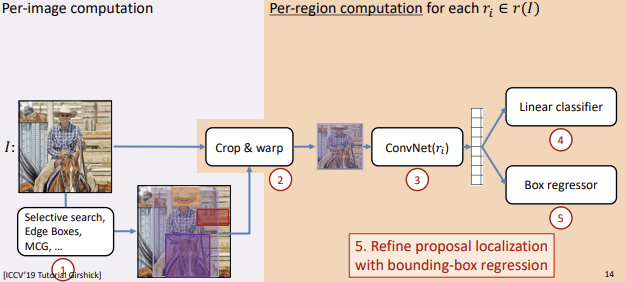
동작과정
- Region Proposal(ex.Selective Search)
- 먼저 이미지에 Selective Search같은 방법을 통해 약 2000개의 ROI(Region of Interest)를 추출한다.
- Warping
- 각 ROI는 모두 다른 크기를 갖고 있기 때문에 CNN Architecture에 넣기 위해 모두 동일한 크기를 갖도록 Warping을 해준다.
- Feature추출
- Warping된 ROI를 CNN모델에 넣어 Feature를 추출한다.
(CNN: VGG, Alex)- Classification 및 Box Regression
ⅰ. Classifier: Feature를 SVM에 넣어 Classification
(SVM을 사용하는 이유는 그냥 과거에 나왔던 모델이라 그런듯 함)
ⅱ. Box Regressor: Bounding Box의 정확한 위치를 학습
(Selective Search는 물체의 대략적인 위치만 제공)Box Regression
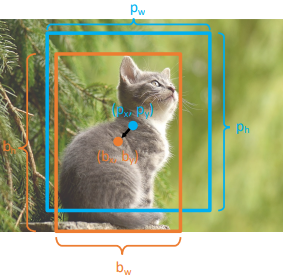
Output 1. 파란색$(p_x, p_y, p_w, p_h) \rightarrow$ Region Proposal
2. 주황색$(b_x, b_y, b_w, b_h) \rightarrow$ Ground Truth
3. Transform $(t_x, t_y, t_w, t_h) \rightarrow$ Prediction
- $b_x = p_x+p_wt_x$
- $b_y = p_y+p_ht_y$
- $b_w = p_we^{t_w}$
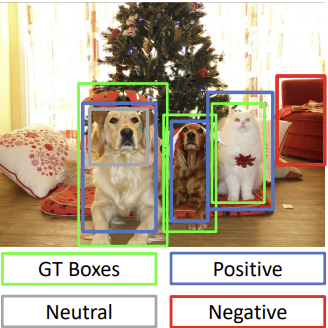
- $b_h = p_he^{t_h}$Training 1. Region Proposal과 Ground Truth의 IOU를 비교하여
Negative Sample과 Positive Sample을 나눈다.
- Positive Sample: 객체가 있는 Box
- Negative Sample: 배경이 있는 Box
2. Training
- Positive Sample: Class와 transform에 대해 학습
- Negative Smple: Class(Background)만 학습문제점
- 연산량 $\Uparrow$
- 모든 ROI에 대해 CNN모델을 통과시켜야 하기 때문에 해야하는 연산이 너무 많다.
- 다양성 $\Downarrow$
- 다양한 크기의 ROI를 강제로 정해진 크기로 Warping해주었다.
- End-to-End학습 불가
- Classifier $\rightarrow$ SVM
- Region Proposal $\rightarrow$ Selective Search
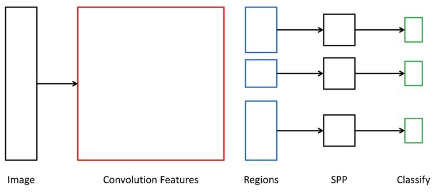
2) SPPNet
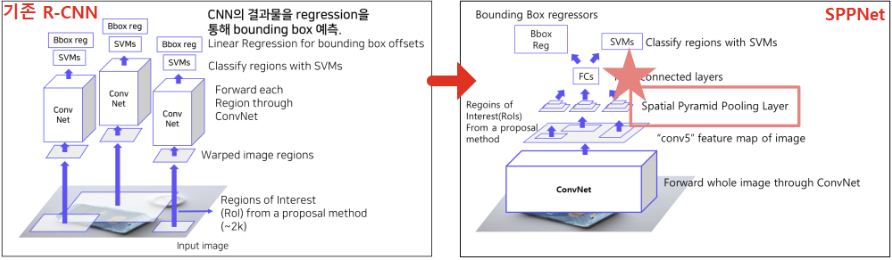
Purpose
R-CNN은 모든 ROI에 대해 CNN모델을 통과시켜야 한다.
$\rightarrow$ CNN을 통해 Feature를 먼저 얻은 후 Selective SearchR-CNN은 다양한 크기의 ROI를 하나의 정해진 크기로 Warping해주어야 한다. $\rightarrow$ Spatial Pyramid Pooling Layer
동작과정
- Feature 추출
- 이미지를 CNN모델에 넣어 Feature Map을 추출한다.
- Region Proposal
- Feature Map에 대해 Region Proposal 방법(Selective Search)을 적용해 ROI를 선별한다.
- SPP Layer
- ROI들에 각각 SPP(Spatial Pyramid Pooling) Layer를 통해 고정된 크기의 Feature를 얻는다.
- Classification 및 Box Regression
ⅰ. Classifier: Feature를 SVM에 넣어 Classification
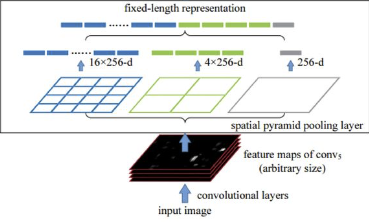
ⅱ. Box Regressor: Bounding Box의 정확한 위치를 학습Spatial Pyramid Pooling
- Spatial Bins의 총 개수를 결정
- 이 개수는 입력으로 들어온 ROI를 표현하는 고정된 길이의 Feature가 된다.
(ex.21 bins=[4x4, 2x2, 1x1])Spatial Bin을 얻기 위한 Stride와 Window Size 설정
(ex.ROI = 13x13일 경우Stride = 4,Window Size = 5로 설정하여 Max Pooing을 수행할 경우Spatial Bin = 3x3을 얻을 수 있다.)Spatial Bin추출
- Flatten
- 모든 Spatial Bin을 Flatten하고 연결시켜 고정된 길이의 Feature를 얻는다.
문제점
- End-to-End학습 불가
(참고한 블로그)
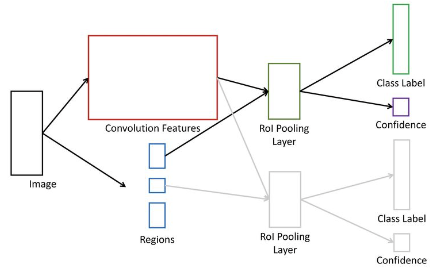
3) Fast R-CNN
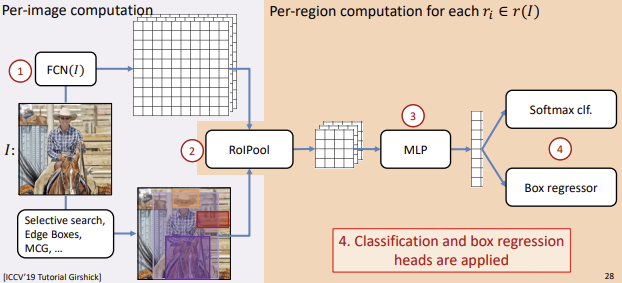
Purpose
R-CNN을 해결하기 위해 SPPNet과는 조금 다른 시도를 하였다.
R-CNN은 모든 ROI에 대해 CNN모델을 통과시켜야 한다.
$\rightarrow$ CNN을 통해 Feature를 먼저 얻은 후 ROI를 여기에 ProjectionR-CNN은 다양한 크기의 ROI를 하나의 정해진 크기로 Warping해주어야 한다. $\rightarrow$ ROI Pooling
동작과정
- Region Proposal
- Image에 대해 Region Proposal 방법(Selective Search)을 적용해 ROI를 선별한다.
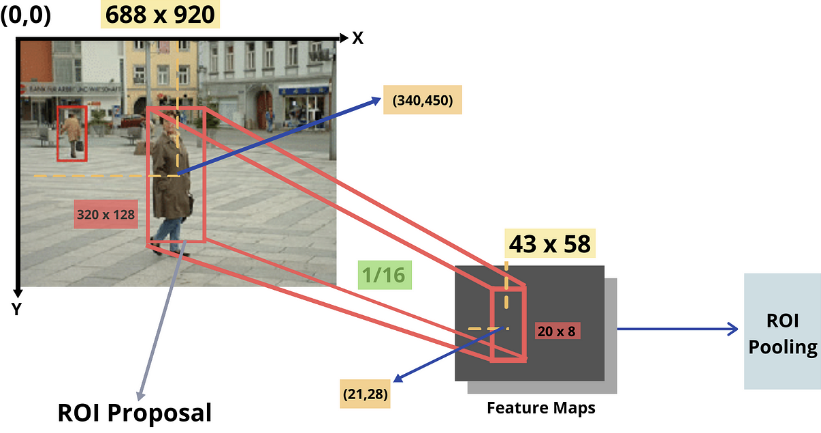
ROI Projection
ⅰ. 이미지를 CNN모델에 넣어 Feature Map을 추출한다.
ⅱ. 이 Feature Map에 ROI를 투영(Pojection)한다.
(ROI를 Feature Map에 맞게 resize해서 크기를 맞춘다.)
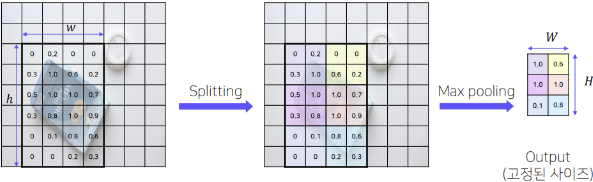
- ROI Pooling
- ROI Projection을 통해 얻은 ROI에 대해 ROI Pooling을 통해 일정한 크기의 Feature를 얻는다.
- Classification 및 Box Regression
ⅰ. Classifier: Feature를 Softmax FCL에 넣어 Classification
ⅱ. Box Regressor: Bounding Box의 정확한 위치를 학습ROI Pojection & ROI Pooling
ROI Pojection ROI Pooling 이미지에서 얻은 ROI를 그대로
Convolution Feature Map에 PojectionSPP Layer와 마찬가지로
bin으로 나누고 bin별로 Max pooling(추가학습: Hierarchical Sampling)
문제점
- End-to-End학습이 불가
(Selective Search를 사용)
4) Faster R-CNN
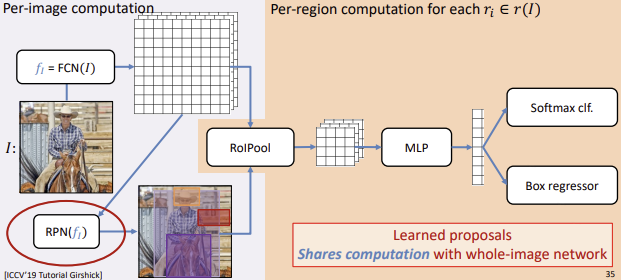
Purpose
- Region Proposal에서 Selective Search를 사용하는 것은 다음과 같은 문제가 있다.
- End-to-End 학습 불가
- Time Complexity (2000개의 후보중 단 몇개만 고르게 됨)
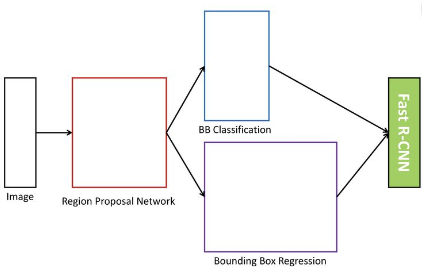
$\rightarrow$ RPN(Region Proposal Network)
동작과정
- Feature 추출
- 이미지를 CNN모델에 넣어 Feature Map을 추출한다.
- Region Proposal Network
- RPN을 통해 ROI 후보를 얻고 NMS를 통해 ROI를 결정한다.
- ROI Projection & ROI Pooling
- ROI를 Feature Map에 Pojection하고, 이 영역에 대해 ROI Pooling을 수행한다.
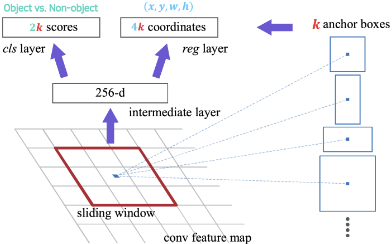
Region Proposal Network(RPN)
- Anchor 생성
- 우선 CNN모델에서 얻은 Feature Map에서 Cell을 Anchor로 지정한다.
- 이 Anchor를 중심으로 K개의 Anchor Box를 생성한다.
($K=len(Scale) \times len(ratio)$)
- Scale: Box자체의 크기 개수
- Ratio: Box의 가로-세로 비율 개수- Classification & Regression
ⅰ. Classification: 배경에 대한 Anchor Box를 제외하기 위해 Objectness를 학습한다
$\rightarrow K$ 개의 Cls Layer (배경O, 배경X)
ⅱ. Regression: 물체에 대한 Anchor Box의 정확한 위치를 학습한다.
$\rightarrow K$ 개의 Reg Layer (dx, dy, dw, dh)(참고: k+Sigmoid로도 가능하지만 논문에서는 2k+Softmax 로 구현하였다고 함)
- NMS
- NMS를 통해 ROI를 얻는다.
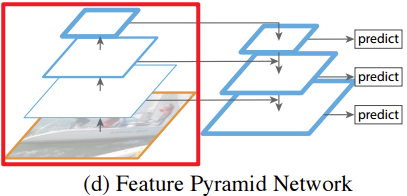
5) Feature Pyramid Network(FPN)
Purpose
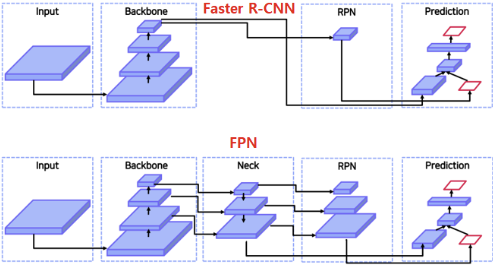
- Faster R-CNN은 큰 Receptive Field를 갖는 Feature Map을 전달해 주기 때문에, 비교적 작은 물체에 대해서는 성능이 낮아진다.
$\rightarrow$ FPN을 Neck으로 사용Keyword
- Scale Invariance: 크기이 달라져도 Class예측 성능 유지
- Scale Equivariance: 크기가 달라져도 위치 예측 성능 유지
동작과정
Bottom Up: ResNet Top Down: Neck BackBone Model을 통과시켜 Feature Map을 뽑아낸다.
이때, 각 Layer에서 Feature Map을 모두 뽑아야 한다.
(본 논문에서는 Backbone으로 ResNet을 사용하였고,
ResNet의 Pooling 구간을 기준으로 4개를 추출했다.)
ⅰ. Top
: Resolution $\Uparrow$, Feature(Semantic meaning) $\Downarrow$
ⅱ. Bottom
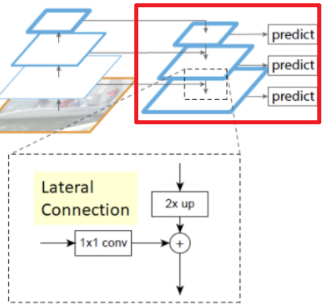
: Resolution $\Downarrow$, Feature(Semantic meaning) $\Uparrow$Bottom Up과정에서 나온 Feature Map과
Upsampling 과정중 나오는 Feature Map을 합친다.
(Elementwise 덧셈)
이때, 두 Feature Map의 크기를 같게 만들어야 한다.
ⅰ. Bottom Up $\rightarrow 1\times 1$ Conv로 C조절
ⅱ. Top Down $\rightarrow$ Upsampling으로 W, H조절
(Nearest Neighbor Upsampling)여기서 Feature Pyramid Network을 사용하지 않고각 층의 Feature Map을 바로 RPN과 연결해 Predict에 사용하면 어떨까 라는 생각을 할 수 있다.
하지만 바로 연결할 경우 low level Feature Map에는 Sementic 정보가 부족하게 되고
High Level Feature Map에는 Localize 정보가 부족하기 때문에 정보 전달이 제대로 되지 않는다.Neck
일반적으로 CNN은 모델의 깊이가 깊어질수록 Receptive Field의 크기가 커진다.
즉, Faster R-CNN은 CNN의 마지막 Layer의 Feature Map만을 사용하기 때문에 작은 물체에 대해서는 성능이 낮아진다고 해석할 수 있다.
Neck은 이 문제를 해결하기 위해 나온 개념으로 Backbone Network와 RPN사이에서 추가적인 작업을 해주는 부분을 의미한다.
FPN의 경우 Neck으로 Feature Pyramid Network를 사용하였다.
ROI Projection
$k = [k_0 + log(\frac{\sqrt {wh}}{224})]$
RPN의 Output으로 Boundbox의
X,Y, 그리고Width와Height를 구할 수 있었다.이제 이를 통해 FPN을 학습시켜야 하는데
현재 “Width”와 “Height”를 위의 식에 대입하면, 해당 Boundbox가 몇번째 Feature Map에서 나온 것인지 알 수 있다.따라서 먼저 위의 식을 통해 K를 구한 후 이를 활용해 해당 Feature Map에 ROI Projection을 수행하도록 한다.