9. Natural Language Processing
Language Models
Natural Language의 핵심은 다음과 같다.
- 의미가 모호함
- 사람마다 문법이 명확하지 않음
즉, 정답/오답을 구분하기 보다는 확률분포를 계산해야 할 필요가 있다.
1. Models
1) Bag-of-Words
단어들의 순서는 전혀 고려하지 않고, 출현 빈도만을 기록하여 수치화하는 표현방법을 말한다.
예를 들어 “I love dog, and I love cat”이라는 문장이 있을경우
bag = {'I': 2, 'love': 2, 'dog': 1, 'and': 1, 'cat':1}
로 표현할 수 있다.Application
그렇다면 이렇게 표현해서 어디에 쓸 수 있을까?
- 정보검색
- Text분류
- $P(Class \vert word_{1:N}) = \alpha P(Class)P(word_{1:N} \vert Class)$
$\approx P(class) \prod \limits_i P(w_i \vert Class)$Limitation
- Sparseness
- 문맥을 고려해서 단어를 구분하지 않음
N-Gram Model
앞의 N개의 (단어/글자)를 고려해 다음에 나올 단어를 유추하는 모델
Bayesian이론에 따라 해당 Sentence가 나올 확률, 즉 $P_{1:N}$는 다음과 같이 정의된다.
$P(W_N \vert W_{1:N-1})P(W_N-1 \vert W_{1:n-2}) … P(W_2 \vert w_1)P(W_1)$ $= \prod \limits_{i=1}^N P(w_i \vert w_{1:i-1})$이때 N-Gram은 앞선 N-1개의 단어만 고려하는 것으로
$\prod \limits_{i=1}^N P(w_i \vert w_{i-1 - n + 2:i-1})$로 표현할 수 있다.이때 주의할 점은 다음과 같다.
- 많이 발생하지 않은 단어/ 학습하지 않은 단어 $\rightarrow$ 확률값을 신뢰할 수 없음
ⅰ. “<UNK>”라는 특별한 토큰을 사용해 표현
ⅱ. Smoothing
$\quad$ - Backoff Model: (N-1)-Gram으로 발생하지 않았을 경우 1-Gram으로 점차 줄여서 확인하는 것
$\quad$ - Linear Interpolation: (N-1)개의 각 Gram으로 Weighted Sum으로 표현하는 것
$\quad \;\, ex)\;P(w_i \vert w_{i-2}, w_{i-1}) = \lambda_3 P(w_i \vert w_{i-2}, w_{i-1}) + \lambda_2 P(w_i \vert w_{i-1}) + \lambda_1 P(w_i)$Application
- Text분류
- $P(Class \vert word_{1:N}) = \alpha P(Class)P(word_{1:N} \vert Class)$
$\approx P(class) \prod \limits_i P(w_i \vert w_{i-1 - n + 2:i-1}, Class)$- N-Gram을 단어단위가 아닌 글자단위로 수행하면 신조어의 의미를 찾는것과 같은 역할도 수행할 수 있다.
Limitation
- Sparseness
- 문맥을 고려해서 단어를 구분하지 않음
2. 문법
1) Grammar(Syntax)
Probabilistic Context Free Grammar Lexicon Context에 상관없이 확률적으로
적용할 수 있는 문법 규칙단어별 품사 규칙


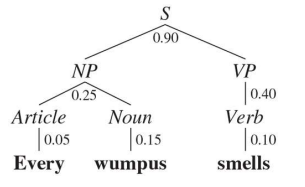
2) Parsing
Chomsky Normal Form
Grammar를 통해 문장의 구조, Syntax/Semantic을 찾아낼 수 있는데 이것을 Parsing이라고 한다.
이를 위해서는 우선 모든 규칙이 Chomsky Normal Form으로 표현되어야 한다.
Chomsky Normal Form에는 터미널기호와 비터미널기호가 있는데, 예를들어 다음과 같다
- Syntactic Rules
- ‘S’ $\rightarrow$ ‘NP’ ‘VP’ $\qquad\;\;$ (문장 $\rightarrow$ 명사구 + 동사구)
- ‘NP’ $\rightarrow$ ‘DET’ ‘N’ $\qquad$ (명사구 $\rightarrow$ 관사 + 명사)
- Lexical Rules
- ‘DET’ $\rightarrow$ ‘the’ $\qquad\;$ (관사 $\rightarrow$ “the”)
- ‘V’ $\rightarrow$ ‘Chased’ $\qquad$ (동사 $\rightarrow$ “Chased”)
CYK Algorithm
Time Complexity: $O(n^3m)$
Space Complexity: $O(n^2m)$


3) Rule-based Translation
In Deep Learning
1. Word Embedding
Sparse Representation
| One-hot Vector | N-Gram Representation | |
|---|---|---|
| 설명 | N개의 단어를 N차원 벡터로 표현 | N-1개의 단어에 기반해 다음에 나올 word의 확률을 구하는 것 |
| 예시 | word = {‘R’:[1, 0, 0], $\quad \qquad$ ‘G’:[0, 1, 0], $\quad \qquad$ ‘B’: [0, 0, 1]}` | $P(w \vert \text{I am}) = \frac{count(\text{I am }w)}{count(\text{I am})}$ $w = \text{handsome, cute, cold, …}$ |
| 단점 | 비슷한 단어끼리 묶을 수 없음 | 여전히 Sparse한 데이터 N의 선택에 의해 Trade-off 발생 |
Sparse Representation은 많은 저장공간을 필요로 하기 때문에,
보통 모델 학습을 위해서는 Dense Representation이 필요하다.
(ex. 강아지 = [0.2, 1.8, 1.1, -2.1, 1.1, 2.8, …])
이에 표현 방법을 Dense Representation으로 바꾸어주는 Word Embedding이 반드시 필요하고,
이로써 얻을 수 있는 이점은 다음과 같다.
- Low Dimensional
- 비슷한 단어들끼리 가깝게 표현 가능
- Vector Arithmetic
(France - Paris = Greece - Athens)
Deep Learning을 통해 Word Embedding을 수행할 수 있는데, 이는 주로 Classification이나 Prediction과 같은 특정 Task를 수행하면서 생성된 Weight들을 사용하게 된다.
1) Bidirectional RNN
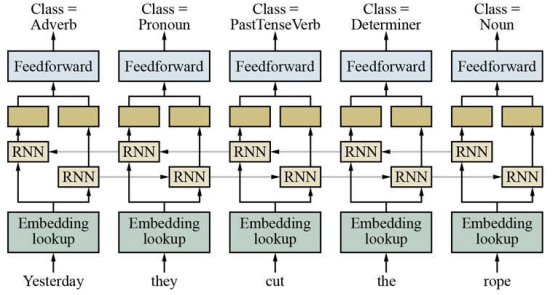
ⅰ. Sparse Representation으로 표현된 단어를 Embedding Lookup 모듈에 넣는다.
ⅱ. 이 결과를 Bidirectional RNN과 FeedFoward Network를 사용해 해당 단어의 Class(품사)를 예측한다.
ⅲ. 이 Embedding Lookup 모듈들을 모아 Table을 만든 후 Word Embedding으로 사용한다.
2) Contextual Representations
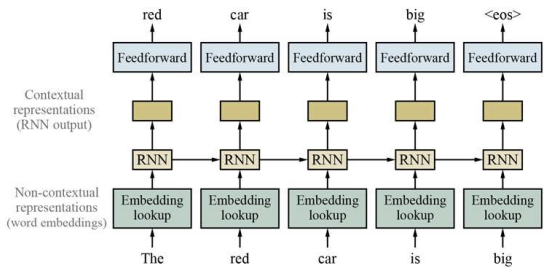
ⅰ. Sparse Representation으로 표현된 단어를 Embedding Lookup 모듈에 넣는다.
ⅱ. 이 결과를 RNN과 FeedFoward Network를 사용해 다음에 나올 단어를 예측한다.
ⅲ. 이 Embedding Lookup 모듈들을 모아 Table을 만든 후 Word Embedding으로 사용한다.
문제점
일방향 RNN을 사용하기 때문에 앞뒤 단어를 고려할 수 없다.
때문에 다음과 같은 상황에서 문제가 발생한다.
- 다의어
- 단어의 뉘앙스
- 관용구
그렇다고 양방향 RNN을 사용할 경우 다음에 나올 단어를 미리 알 수 있기 때문에 학습이 제대로 되지 않는다.
3) Masked Language Model
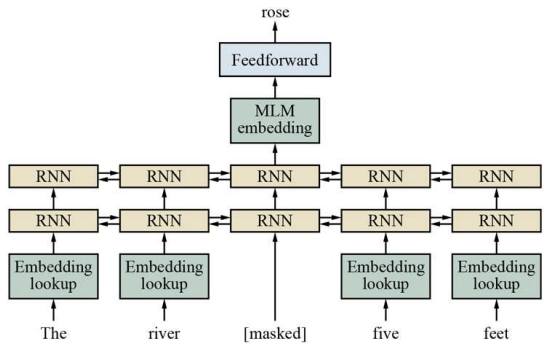
ⅰ. Sparse Representation으로 표현된 단어를 Embedding Lookup 모듈에 넣는다.
ⅱ. 이 결과를 BidirectinaRNN과 FeedFoward Network를 사용해 다음에 나올 단어를 예측한다. $\quad \rightarrow$ 이때, 예측하고자 하는 부분에 대해서는 Mask를 씌워 양 방향의 문맥을 고려해 추측하도록 한다.
ⅲ. 이것을 각 단어별로 수행한다.
2. Model
1) Bert
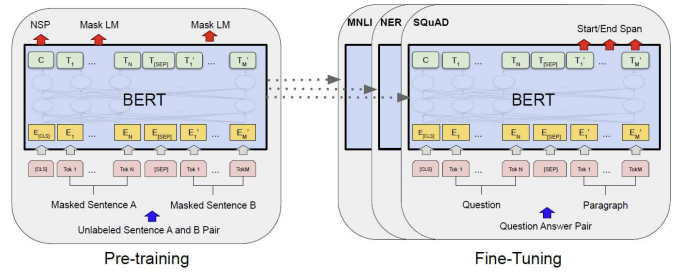
Task
- Random하게 가려진 단어 예측
- Next Sentence prediction
ⅰ. Transformer를 사용한 Masked Language Model을 통해 위의 두 Task를 순차적으로 학습
ⅱ. Pretrained된 Bert를 Finetuning하여 Classification등의 Downstream Task수행
$\Rightarrow$ 양방향 문서표현(임베딩) 모델
2) GPT
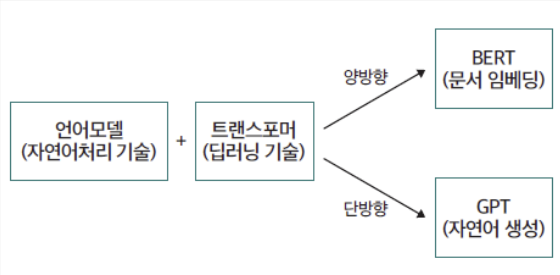
N-Gram문제를 Transformer를 사용하여 푸는 것.
$\Rightarrow$ 단방향 문장 생성 모델
GPT1: Unsupervised + Fine Tunning
GPT2: Unsupervised
GPT3: Unsupervised + Incontext Learning
GPT4: Unsupervised + Multimodal