[Paper Review] iBOT: Image BERT Pre-Training with Online Tokenizer
Source
Contents
0. Abstract
iBOT은 MIM기반의 Self-Supervised Learning 프레임워크이다. iBOT은 Online Tokenizer를 만들고 이를 Target model로 Self-Distillation하여 Mask Prediction을 수행한다. 이때, Online Tokeninzer는 Visual Semantic을 얻기 위한 Teacher Network이다. 즉, Online Tokenizer는 MIM Objective와 함께 Multi-stage training pipeline을 통해 학습되는 구조를 갖는다.
(※ 기존의 BEiT는 사전학습된 Visual Tokenizer와 Mask Prediction을 위한 Image Encoder가 필요했다. 즉 사전학습이라는 과정을 제거하기 위해 Self-distillation을 활용한 논문이다.)
1. Introduction
Previous Work(MLM)
Masked Language Modeling (MLM)은 입력 토큰 중 일부를 랜덤하게 마스킹하고 이를 재구성하는 방식으로 언어 모델의 사전 학습을 수행하며, 언어 모델링의 표준으로 자리 잡았다. MLM 방식은 대규모 모델 및 데이터셋에 대한 확장성(scalability)을 입증하며 언어 작업에서 중요한 역할을 하고 있다. 하지만, Vision Transformer (ViT)에 대해 이와 유사한 방식인 Masked Image Modeling (MIM)의 가능성은 아직 충분히 탐구되지 않았다. 기존의 비지도 학습 방식(MoCo, DINO)은 주로 글로벌 뷰(global views)에 초점을 맞추며, 이미지 내부의 로컬 구조(local structures)를 간과하는 경향이 있다.
(※ Contrastive Learning이나, Distillation Model같은 경우 단순히 Class Token의 Output만을 비교 대상으로 하기 때문에 Global한 정보에 초첨을 맞춘다고 언급한 듯 하다.)
Previous Work(MIM)
MLM에서 사용되는 Lingual Tokenizer처럼 MIM에서도 Visual Tokenizer가 사용된다. 이 Visual Tokenzier는 Mask Patch를 학습하기 위한 지도신호(Supervisory Signals)로써 사용된다. 하지만 언어의 경우 단어의 빈도같은 통계적인 방법을 사용해 Lingual Semantic을 얻을 수 있지만, 이러한 방법은 이미지에서 활용하기 힘들다. 따라서 기존에는 먼저 Tokenizer에 Visual Semantic정보를 학습시키고, 이를 Target Model의 학습에 사용하는 방식 (Multi-stage pipeline)으로 사용했다. 하지만 잘 생각해보면 Tokenizer와 Target Model의 Object는 모두 Visual Semantic이라는 공통점이 있기에 이를 Single-stage pipeline으로서 구성할 수 있다.
(※ Multi-stage pipeline: SiT, BEiT)
Approaches
위에서 언급된 문제를 해결하기 위해 iBOT이라는 새로운 Framework를 제안한다. iBOT은 MIM을 Tokenizer로부터의 Knowledge Distillation문제로 정의한다. 그리고 이를 기반으로 twin teacher구조의 Self-Distillation Framework(Teacher와 Student의 구조가 같은)를 만든다. 이때, Target Network는 masked image를, Online Tokenizer는 original image를 입력으로 받게 되고, 학습 목표는 Target Network가 받은 masked image를 Online Tokenizer의 original image의 output으로 복원하는 것이다. 이 과정에서 iBOT은 Online Tokenizer를 통해 기존 MIM의 두가지 문제점을 다음과 같이 해결한다.
- Class Token을 통해 High level visual semantics를 점진적으로 학습
- Pre-training과정 없이 MIM과 Tokenizer를 공동으로 최적화
2. Preliminaries
2.1) Masked Image Modeling as Knowledge Distillation
- MIM은 Image token sequence $(x =\begin{Bmatrix} x_i \end{Bmatrix}^N_{i=1})$에 대해 먼저 Random mask$(\mathcal{m} \in \begin{Bmatrix} 0, 1 \end{Bmatrix}^N)$를 적용한다.($N$은 Token 개수)
Input patch token중 마스크를 씌울 Token($\tilde{x} \triangleq \begin{Bmatrix} x_i \vert m_i = 1 \end{Bmatrix}$)은 $e_{[MASK]}$라는 Learnable Token으로 바꾼다.
$\rightarrow$ 즉, \(input = \hat{x} \triangleq \begin{Bmatrix} \hat{x}_i \vert (1-m_i)x_i + m_ie_{[MASK]} \end{Bmatrix}^N_{i=1}\)이다MIM은 이 $\hat{x}$를 $\tilde{x}$로 복구하는 문제이다.
$\rightarrow \underset{\theta}{\min} -\sum_{i=1}^N m_i \cdot \log q_\theta(x_i \vert \hat{x}) $- BEiT에서는 $\phi$로 사전학습된 discrete VAE $P_\phi$를 사용해서 모델의 Output에 Softmax를 취한 결과인 $P_\theta$를 학습시키는 Knowledge Distillation문제로 MIM을 변형하였다.
$\rightarrow \underset{\theta}{\min} -\sum^N_{i=1}m_i \cdot P_\phi(x_i)^T log P_\theta(\hat{x}_i)$※ 이때 $P(\cdot)$은 사전에 정의된 K(i.e 8192)차원의 확률분포이다.
2.2) Self-Distillation
- Self-Distillation model인 DINO에서는 사후 확률 분포(Tokenizer가 먼저 학습되어야 하기 때문에)인 $P_\phi(x)$ 대신에 자신의 Past Iteration을 활용한 $P_{\theta’}$를 사용한다.
- 이를 위해, 먼저 Tranining set $\mathcal{I}$에서 image($x \sim \mathcal{I}$)를 Sampling하고 Augmentation을 적용해 distorted view $u, v$를 얻는다.
- 그 후 각각의 view와 [CLS]토큰을 함께 모델에 입력하고 [CLS]토큰의 Output을 얻는다.
$\rightarrow v_t^{[CLS]} = P_{\theta’}^{[CLS]}(v)$와 $u_s^{[CLS]} = P_{\theta}^{[CLS]}(u)$- 마지막으로 Cross-entropy를 사용해 Knowledge distillation을 구성한다.
\(\rightarrow \mathcal{L}_{[CLS]} = -P_{\theta'}^{[CLS]}(v)^T log P_{\theta}^{[cls]}(u)\)- 위의 Loss를 사용해 Student Network를 학습하고 Teacher Network의 Parameter($\theta’$)는 Student Netowrk의 Parameter($\theta$)에 EMA(Exponentially Moving Average)를 적용해 설정한다.
3. Methods
위의 Preliminaries에서 다룬 두 식을 살펴보면 비슷하다는 것을 알 수 있다. 즉, BEiT에서 사용하는 Visual Tokenizer의 Parameter $\phi$는 자신의 Past Iteration을 의미하는 $\theta’$로 대체할 수 있고, iBOT은 이를 통해 MIM을 Self-distillation문제로 정의한다.
여기서 내가 생각하는 핵심은 다음과 같다.
- BEiT개선
- Visual Token으로써 Past Iteration에서 자신이 만들었던 Patch Embedding의 Output을 사용
- BEiT개선
- DINO개선
- DINO에서는 [CLS] Token의 Output만을 사용해 학습했기에 Global한 정보만을 활용했지만, 각 Patch를 학습시키는 MIM을 같이 도입하여 Local한 정보도 활용할 수 있도록 함
- DINO개선
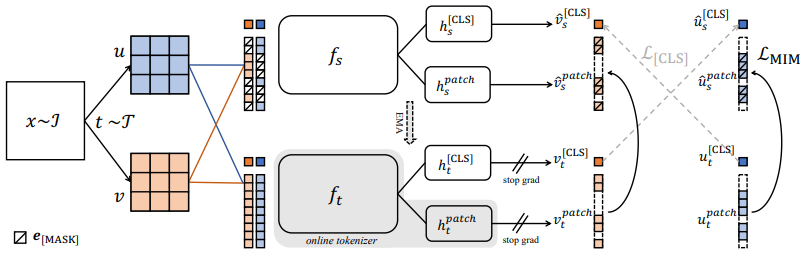
3.1) Framework
- 먼저 BEiT와 마찬가지로 2개의 View($u, v$)에 Blockwise masking을 적용해 Masked View($\hat{u}, \hat{v}$)를 얻는다.
- Masked View $\hat{u}$의 각각의 Patch를 Student Network에 넣어 Output을 얻는다.
\(\rightarrow \hat{u}^{patch}_s = P^{patch}_\theta(\hat{u})\)- Masking되지 않은 View $u$에서 각각의 Patch를 Teacher Network에 넣어 Output을 얻는다.
\(\rightarrow u^{patch}_t = P^{patch}_{\theta'}(u)\)- Cross Entropy를 활용해 Loss를 정의하고 Distillation Framework를 만든다. \(\rightarrow \mathcal{L}_{MIM}^u = -\sum^N_{i=1} m_i \cdot P^{patch}_{\theta'}(u_i)^T \log P^{patch}_\theta (\hat{u}_i)\)
\(\rightarrow \mathcal{L}_{MIM} = \frac{\mathcal{L}_{MIM}^u + \mathcal{L}_{MIM}^v}{2}\)- 이때, Teacher Netowrk는 Backbone과 Projection Head로 이루어져있고, 별도의 Train과정 없이 Visual tokenizer의 역할을 한다.
\(\rightarrow \text{Teacher} = h_t^{patch} \circ f_t\)- 또한, Mask Prediction은 같은 Image에 대해서 수행하지만 Class Token의 Distillation은 Cross-view image를 통해 수행한다. 이 과정을 통해 Semantically-meaningful한 정보를 얻을 수 있다.
- \(\mathcal{L}_{total} = \mathcal{L}_{[CLS]} + \mathcal{L}_{[MIM]}\)로 설정하고, [CLS] Token의 Projection head와 Patch Token의 Projection head의 Parameter를 공유하게끔 설정한다.
$\rightarrow h_s^{[CLS]} = h_s^{patch}, h_t^{[CLS]} = h_t^{patch}$※ $L_{[CLS]}$는 Preliminaries 참조
3.2) Implementation

B. Multi-Crop
즉, iBOT은 Masked Prediction과 Self-Distillation을 결합한 방법임을 알 수 있다. 이때, Masked된 이미지에 대해서 DINO에서 사용했던 Multi-Crop은 어떻게 활용해야하는지 알아보는 Section이다.
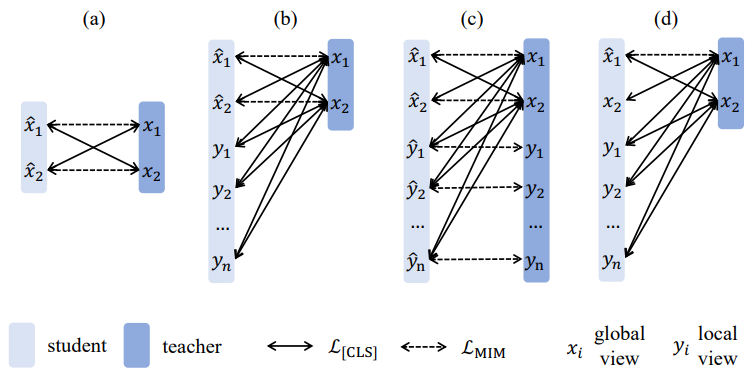
먼저 Multi Crop을 MIM과 함께 사용할 경우 Teacher Network는 Global Crops를 입력으로 받고, Student Network는 Global + Local Crops를 입력으로 받아야 한다. 하지만 이때, Masking된 Global Patch로부터 Local한 정보를 복원할 때에는 Mismatch가 많이 발생할 수 있다는 것을 알 수 있다. 특히, Local한 Patch에 Masking을 적용하면 의미있는 정보가 대부분 사라지게 된다. 이를 해결하기 위해 Local Patch에 대해서는 Masking을 수행하지 않도록 하는(위 그림의 (b)) 방법을 채택한다.
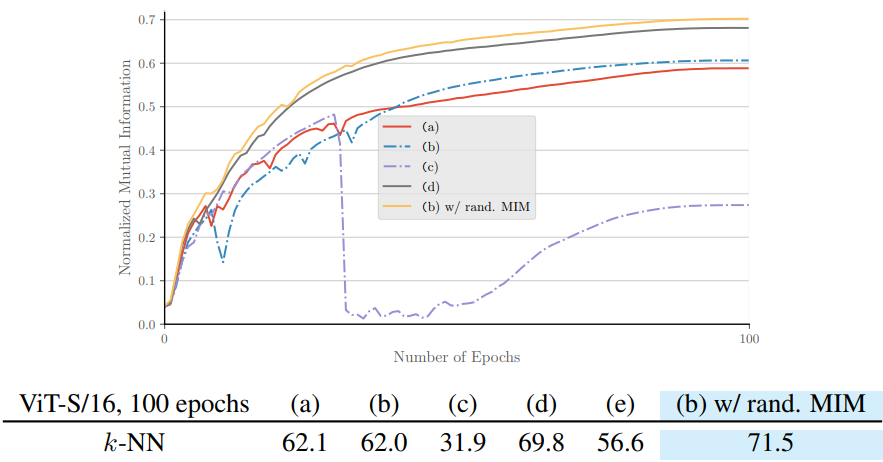
각각의 방법에 대한 실험 결과 또한 (b)가 가장 좋았던 것을 알 수 있다.