[Paper Review] DINOv2: Learning Robust Visual Features without Supervision
Source
Contents
0. Abstract
최근 자연어 처리(NLP) 분야에서 대규모 데이터로 사전학습된 모델의 성공은 컴퓨터 비전에서도 비슷한 “Foundation Model”의 가능성을 열어주었다. 이러한 모델은 범용적인 시각 특징(General-purpose Visual Features)을 생성해, 미세 조정 없이도 다양한 이미지 분포와 작업에 활용될 수 있다.
DINOv2 연구는 기존의 자기 지도 학습(Self-supervised Learning) 방법들이 충분히 큐레이션(정제된)된 대규모 데이터셋을 사용하면 이러한 범용 시각 특징을 학습할 수 있음을 보여준다. 우리는 기존의 방법들을 살펴보고 Data와 Model의 크기를 모두 늘리기 위해 다양한 기법들을 조합해본다. 대부분의 Contribution은 학습의 scale을 늘리고 안정화시키는 것에 집중하고 있다.
Contribution
- Data Pipeline
- 자동화된 Pipeline을 통해 다양하고 정제된 dataset을 얻는 방법
- Data Pipeline
- Model
- 10억개의 Parameter를 갖는 ViT를 더 작은 모델로 Distillation하여 General Purpose를 갖는 Feature를 얻음.
- Model
1. Instruction
Previous Work(Text-guided Pregraining)
자연어 처리(NLP) 분야에서는 Task-agnostic Pretrained Representations이 표준이 되었다. 이러한 표현들은 미세 조정(Fine-tuning) 없이도 바로 사용할 수 있으며, 특정 태스크에 맞춘 모델보다도 뛰어난 성능을 보여주었다. 이를 바탕으로 컴퓨터 비전에서도 Foundation Models이 등장할 것으로 기대되는데, 이러한 모델들은 이미지 수준(ex. 이미지 분류)과 픽셀 수준(ex. 세그멘테이션) 작업에서 바로 사용 가능한 Visual Feature를 생성해야 한다. 현재까지 가장 유망한 Vision Foundation Model들은 Text-guided Pretraining을 중심으로 발전하고 있다. 하지만 이러한 방법들은 Text로는 Image의 풍부한 정보들을 모두 표현하지 못할 뿐더러 학습을 위해서는 Text-image 데이터 뭉치가 필요하기에 raw data만으로 학습하기 어렵다는 한계가 있다.
Previous Work(Self-Supervised Learning)
Self-supervised Learning (SSL)은 이미지 자체에서 특징을 학습하는 방법으로, 텍스트 기반 사전학습의 대안으로 주목받고 있다. 이는 Language Modeling과 같은 Pretext task와 개념적으로 유사하고, Image level과 Pixel level의 정보를 모두 학습할 수 있다. 하지만 대부분의 Self-Supervised Learning연구는 ImageNet과 같이 적은 수의 정제된 데이터만을 가지고 연구되었기 때문에 좋은 Feature를 학습할 수 없었다.
Approaches
따라서 이 연구에서 우리는 Self-Supervised Learning이 많은 양의 정제된 데이터를 가지고 학습할 때, General-purpose Visual Feature를 학습할 수 있을지에 대한 연구를 진행할 것이다. 그리고 Image와 Patch Level의 Feature를 모두 다룰 수 있는 기존 기법(iBOT)의 Design Choice를 “Large”, “Curated” Data에 맞게 수정하고 개선하고자 한다. 그 결과 기존 방법 대비 학습 속도를 2배 빠르게 하고, 메모리 사용량을 3배 감소시킬 수 있었다.
- Automatic Pipeline
- 이를 위해 Uncurated image를 필터링하고, rebalance하는 자동화된 데이터 Pipeline을 구축했다. 이는 NLP분야의 데이터 처리 기법에서 영감을 받아 설계되었고, Manual Annotation이나 Metadata없이도 데이터를 효율적으로 처리할 수 있게 한다.
- Automatic Pipeline
- DINOv2
- 그리고 우리는 DINOv2라는 모델을 제안하고, 위에서 얻은 “Large”, “Curated” Data를 통해 학습한 결과 매우 Competitive한 모델을 얻을 수 있었다.
- DINOv2
2. Related Work
Intra-image self-supervised training
Self-supervised Learning의 첫 번째 방법론은 이미지 자체에서 신호를 추출하는 Pretext Tasks에 집중한다. 이러한 작업은 이미지의 일부분을 예측하거나 변형을 복원하는 등 이미지의 일부를 학습 목표로 삼는다. 다음과 같은 Idea들이 있다.
- Predicting Context
주어진 Patch의 상대적인 위치를 예측하는 Pretext Task - Re-Colorizing
흑백 이미지를 Color이미지로 변환하는 Pretext Task - Predicting Transformation
이미지의 변형(회전 등)을 예측하는 Pretext Task - Inpainting, Patch Re-Ordering, Masked Prediction
하지만 위의 방법들로부터 얻은 Feature들은 Downstream Task에서 Finetuning이 필요하다는 단점이 있다.
Discriminative self-supervised learning
Self-supervised Learning의 두 번째 방법론은 이미지 또는 이미지 그룹 간의 판별 신호(Discriminative Signals)를 사용하여 특징을 학습하는 방법이다. 이 접근법은 초기 딥러닝 연구에 뿌리를 두고 있으며, 인스턴스 분류와 클러스터링 기법을 기반으로 발전했다.
- Instance-level Objective
- CPC, MoCo, SimSiam, SimCLR, BYOL, DINO
- Instance-level Objective
- Clustering based
- Deep Cluster, SeLa, SwAV
- Clustering based
위의 방법들은 ImageNet과 같은 벤치마크에서는 좋은 성능을 보이지만, 대규모 모델과 데이터셋으로 확장하기 어렵다는 단점이 있다.
Scaling self-supervised pretraining
최근 연구들은 Self-supervised Learning (SSL)의 확장성(Scaling Abilities)에 집중하며, 특히 데이터와 모델의 규모가 학습 성능에 미치는 영향을 분석하고 있다. 대부분의 연구들은 “Large”, “Uncurated” data를 활용해 Model의 Scale을 늘리는 연구가 많다.
- Unsupervised pre-training of image features on non-curated data
- Self-supervised pretraining of visual features in the wild
- Scaling and benchmarking self-supervised visual representation learning
- Self-supervised learning from uncurated data
- Vision models are more robust and fair when pretrained on uncurated images without supervision
하지만 대부분의 방법들은 “Uncurated”, 즉 data의 품질 저하로 인해 성능이 제한되는 문제가 발생하였다.
Automatic data curation
이번 연구의 데이터셋 구축 방식은 이미지 검색(Image Retrieval) 분야에서 영감을 받았다. 특히 시각적 유사성을 활용해 데이터를 필터링하고 증강하는 접근을 사용하며, 이는 기존의 Semi-supervised Learning이나 메타데이터 활용 기법과 차별화될 수 있다. Pretrained된 Encoder와 metadata에 의존했던 기존의 방법들과는 달리, 우리는 Visual Similarity만을 활용해 이미지를 필터링하고 증강한다. 이는 기존의 Text Curation pipeline으로 사용되는 Ccnet에서 영감을 받았다.
3. Data Processing
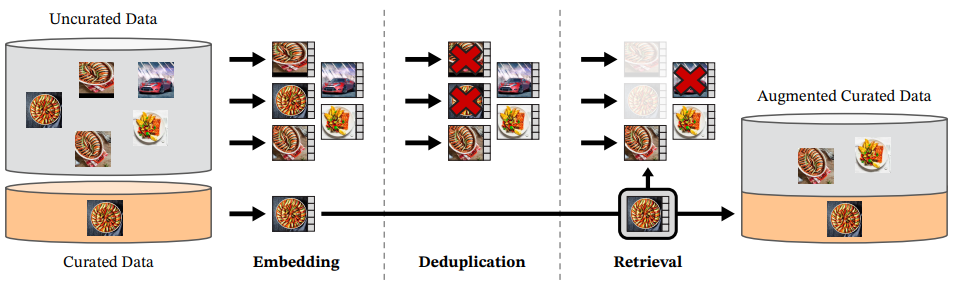
우리는 LVD-142M이라는 Curated Dataset을 제작했는데, 이는 대규모의 Uncurated data pool에서 몇몇 Curated dataset과 비슷한 이미지를 검색하여 구성하였다. 이때 이 Pipeline은 어떠한 Metadata나 text를 사용하지 않았다.
Data Source
먼저 Curated Dataset은 ImageNet-22k와 Google Landmarks등 몇몇 잘 정제된 Dataset을 포함하여 구성하였다. 그리고 Uncurated Data Source의 경우 Publicly available한 repository의 <img> tag에서 이미지 URL을 가져와 1.2B개의 Image를 얻었다.
(※ 가져오기 전에 PCA hash duplication, NSFW Filtering, Blurring indentifiable face를 적용함)
Deduplication
그 후 Uncurated data에서 중복된 이미지들을 Copy detection pipeline을 따라 제거하여 Dataset의 diversity를 증가시켜주었다.
Self-supervised image retrieval
우리는 LVD-142M Dataset을 구축하기 위해 위에서 모았던 Uncurated Dataset에서 Curated Dataset을 검색(Retrieving)하는 방식을 사용하였다. 이를 위해 우선 ImageNet-22k로 사전학습한 ViT-H/16을 사용해 Image Embedding 생성한다. 그리고 이 Embedding간의 Cosine Similarity를 계산해 이미지간의 Distance를 구하였다.
\[\text{Cosine-similarity}(f(s), f(r)) = \frac{f(s) \cdot f(r)}{\Vert f(s) \Vert_2 \Vert f(r) \Vert_2}\]그 후 K-means Clustering을 하여 Uncurated Dataset을 나눈다. 그리고 Query dataset이 크다면 Query Image에 해당하는 Cluster에서 4의 Nearest Neighbor를 적용하고, 작다면 Query Image에 해당하는 Cluster에서 M개의 이미지를 Sampling한다. 이 때, 시각적으로 검토한 결과 N이 4보다 크지 않은 경우 검색된 이미지의 품질이 좋은 것을 확인하였다.
4. Discriminative Self-supervised Pre-training
이 연구에서는 DINO와 iBOT의 Loss를 결합하고 SwAV의 Centering기법을 사용하여 Self-Supervised Learning Method를 구성했다. 또한 Feature를 Spread하기 위한 Regularizer와 짧은 고해상도 Training 단계를 추가하였다.
Image-level objective (DINO)
\[\mathcal{L}_{DINO} = - \sum p_t \log p_s\]DINO에서는 Teacher Network와 Student Network 각각에서 뽑아낸 Feature Map의 Cross-entropy loss를 비교한다.
이때, Feature Map은 ViT와 MLP head를 통과한 [CLS] Token의 Output이고, 이를 “Prototype Score”라고 부른다. 그 후 Teacher Network와 Student Network에서 얻은 Prototype Score에 Softmax를 각각 적용하여 $p_s$와 $p_t’$를 얻을 수 있고 $p_t’$에는 Moving Average나 Sinkhorn-Knopp과 같은 Centering기법을 적용하여 $p_t$를 얻는다. 그리고 이 둘의 Cross-entropy를 비교하여 Loss를 설계할 수 있다. 마지막으로 Student Network를 학습하고, Teacher Network는 EMA를 통해 Parameter를 설정한다.
Patch-level objective (iBOT)
\[\mathcal{L}_{iBOT} = -\sum_i p_{ti} \log p_{si}\]Student Network의 Input Patch에 random하게 mask를 적용하고 Student Head를 통과시킨다. Input Patch에 Masking된 부분을 골라 Teacher Network에 입력으로 주고 이때의 Output을 signal로써 사용하여 Student Network를 학습시킨다. DINO와 마찬가지로 Softmax와 Centering을 적용하고 Teacher Network는 EMA를 통해 Parameter를 설정한다.
Untying head weights between both objective
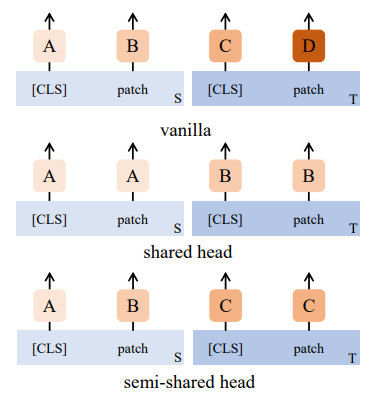
기존의 iBOT연구에서는 CLS Head와 Patch Head의 가중치를 묶는 방식의 성능이 좋았었다. 하지만 실제 실험 결과 Scale상황에서 가중치를 분리하는 것이 더 좋은 성능을 보였다.
Sinkhorn-Knopp Centering (SwAV)
Weighted ensemble self-supervised learning라는 논문에서는 DINO의 Teacher Network의 Centering Step을 Sinkhorn-Knopp을 사용하는 것이 더 좋다고 하였다. 따라서 우리는 이 SK Algorithm을 3번 적용하였다.
KoLeo Regularizer
\[\mathcal{L}_{koleo} = -\frac{1}{n} \sum^n_{i=1} \log(d_{n, i}) \qquad, d_{n, i} = \underset{j \neq i}{\min} \Vert x_i - x_j \Vert\](※ $d_{n, i}$는 $x_i$와 Batch안의 다른 Point들간의 minimum distance)
KoLeo정규화는 Feature가 Batch 내에서 균일하게 퍼지도록 하여 Collapse를 방지한다. 또한 이 Regularizer를 적용하기 전에 $l_2\text{-normalize}$를 적용한다.
Adapting the resolution
이미지 해상도를 높이는 것은 작은 물체가 낮은 해상도에서 사라지는 segmentation 또는 detection과 같은 픽셀 레벨 downstream task의 핵심이다. 그러나 고해상도로 학습시키는 것은 시간과 메모리를 많이 요구하기 때문에 사전 학습이 끝나는 짧은 시간 동안 이미지의 해상도를 $518 \times 518$로 높인다.
5. Efficient Implementation
6. Ablation Studies