[Paper Review] Training data-efficient image transformers & distillation through attention
Source
Contents
0. Abstract
최근 Attention에 기반을 둔 신경망이 이미지 분류와 같은 이미지 이해 작업을 처리할 수 있음을 보여주었다. 이렇게 성능이 우수한 Vision Transformer는 대규모 장비를 사용해 수억개의 이미지를 사용해 사전학습되기 때문에 제한이 있었다. 이 연구에서는 ImageNet으로만 학습하여도 경쟁력있는 Transformer모델을 제안한다. 우리는 이 모델을 하나의 컴퓨터에서 3일 안에 학습시킬 수 있었고, ImageNet이외의 데이터를 사용하지 않고 83%의 top-1 정확도를 기록했다. 더 중요한 것은 우리가 Transformer에 특화된 Teacher-Stduent전략을 도입한 것이다. 이것은 Distillation token으로 하여금 Student가 Teacher로부터 attention을 통해 학습할 수 있도록 한다. 우리는 특히 CNN을 교사모델로 할 때, 이 Token-based distillation의 유용성을 보여준다.
1. Introduction
Previous Work(ViT)
CNN이 이미지 분류 Task에서 처음 입증된 후로, 이미지 이해 Task에서 주요 설계 패러다임이 되었다. 이것의 주요 성공 요인은 ImageNet이라고 불리는 큰 학습 데이터를 사용할 수 있었기 때문이다. 또한 NLP에서 Attention기반 모델들의 성공에 따라 CNN 내에서 Attention을 활용하는 Architecture에 대한 관심이 증가했다. 최근에는 몇몇 연구자들이 Trnasformer의 요소를 CNN에 접목한 하이브리드 아키텍처를 제안하기도 했다.
ViT는 NLP에서 직접적으로 계승된 Architecture지만, 원본 이미지 Patch를 image classification의 입력으로 사용한다. ViT논문에서는 대규모 데이터셋을 활용해 Transformer의 뛰어난 성능을 제시하였고, Transformer는 데이터가 부족한 상황에서는 Generalize가 잘 되지 않는다고 결론지었다.
Approaches(DeiT)
본 논문에서는 ViT를 하나의 8-GPU node에서 2~3일 동안(53시간 Pre-training, 20시간 Fine-tuning) 학습하였는데, 이는 CNN과 비교했을 때 비슷한 파라미터 개수와 효율성을 갖는다. 이 모델은 ImageNet만을 유일한 학습 데이터셋으로 하고, ViT Architecture와 timm library에 포함된 개선사항을 바탕으로 한다. 우리의 DeiT는 기존의 결과에 비해 매우 개선된 결과를 보였고 Ablation study에서는 Repeated Augmentation과 같은 성공적인 학습을 위한 Hyperparameter와 핵심 요소들을 자세히 설명한다.
우리는 또 다른 질문, 즉 어떻게 Distillation을 해야하는지에 대한 것을 다룬다. 우리는 Transformer에 특화된 token-based전략을 소개하고, DeiT라고 명명한다. 그리고 기존의 Distillation과 비교했을 때 어떤 이점을 갖고있는지 보여준다.
Summary
요약하자면 우리의 Contribution은 다음과 같다.
우리의 Network는 Convolution을 사용하지 않고, ImageNet만을 사용해 성공적인 결과를 보여주었다. 이 Network는 4개의 GPU를 단일 노드에서 3일동안 학습되었다. 우리의 새로운 두 모델 DeiT-s와 DeiT-Ti는 작은 모델로 ResNet-50과 ResNet-18의 대응 모델로 볼 수 있다.
우리는 Distillation token에 기반한 새로운 Distillation 방식을 소개한다. 이 token은 [CLS] token과 유사한 역할을 하지만 Teacher가 추정한 label을 재현하는데 초점을 맞춘다. 두 token은 transformer에서 attention을 통해 상호작용한다. 이 Transformer특화 전략(Token기반)은 기존의 Distillation방식을 상당한 차이로 능가한다.
매우 흥미롭게도 우리의 Distillation을 사용할 경우, 이미지 transformer가 CNN으로부터 더 많은 정보를 학습할 수 있었다.
우리의 ImageNet-Pretrained 모델은 다양한 Downstream task에서 우수한 성적을 보였다.
이 논문은 다음과 같이 구성된다.
- Section 2에서는 related work를 살펴보고,
- Section 3에서는 transformer를 사용한 이미지 분류에 대해 살펴본다.
- Section 4에서는 우리의 Distillation전략을 소개하고,
- Section 5에서는 실험에 대한 분석과 기존의 CNN이나 Transformer와 비교한다.
- Section 6에서는 자세한 학습 과정에 대해서 살펴보고 ablation study또한 포함되며, DeiT에 주요 요소들에 대해 살펴보고
- Section 7에서 결론을 설명하겠다.
2. Related Work
Image Classification
이미지 분류는 Computer Vision에서 이미지 이해에 대한 측정 지표로 사용하는 주요 요소이다. 이 기술의 발전은 보통 detection과 segmentation의 발전으로도 이어진다. Alexnet이후로 CNN은 이 Benchmark를 지배하며 사실상 표준이 되었다. ImageNet에서의 발전은 CNN 학습 기법의 발전을 반영한다. 그러나 최근에는 CNN과 트랜스포머를 결합한 하이브리드 아키텍쳐가 이미지 분류, 탐지, 그리고 Video등에서 성공적인 결과를 보였다. 최근 ViT는 CNN을 사용하지 않고도 최첨단 기술과의 격차를 좁혔다. 이 성능은 이미지 분류를 위한 CNN이 오랜 시간에 걸친 Tuning과 Optimization의 이점을 가지고 있었다는 점에 비추어 봤을 때, 주목할 만하다. 그러나 Transformer가 효과적이려면 대량의 정제된 데이터로 사전학습 단계를 거쳐야 한다. 본 논문에서는 ImageNet-1k Dataset만으로도 대규모 학습 데이터 없이 높은 성능을 달성했다.
Transformer Architecture
기계번역을 위해 제안되었던 Transformer는 현재 모든 자연어 처리 작업의 표준이 되었다. 이미지 분류를 위한 CNN의 많은 개선 사항은 Transformer에서 영향을 받았다.
Knoledge Distillation
Knoledge Distillation은 강력한 Teacher network가 생성한 Soft label을 Student model이 활용하는 학습 방법이다. 이는 Hard label인 Maximum Score를 사용하는 것이 아니라 Teacher의 Softmax output을 사용하여 Student model의 성능을 개선하는 것을 말한다.
- Teacher model이 더 작은 Student model로 압축된다고 생각될 수 있다.
- teacher의 soft label은 label smoothing과도 비슷한 효과를 낸다.
- teacher의 supervision은 데이터 증강의 효과를 내고, 때때로 image와 label간의 불일치를 초래한다.
예를 들어 매우 큰 풍경의 가장자리에 작은 고양이가 있는 “cat”이라는 라벨을 갖는 이미지가 있을 때, image가 crop된 경우 암묵적으로 label을 변경해야 한다. - 또한 Knowledge Distillation은 student model로 inductive bias를 전이할 수 있다.
예를 들어 Transformer의 teacher model로 CNN을 사용할 경우 Convolution의 Inductive bias를 주입할 수 있다.
우리는 Transformer에 특화된 새로운 Distillation절차를 도입하고 그 우수성을 보여줄 것이다.
3. Vision Transformer
이 Section에서는 Vision Transformer와 관련된 기초 내용들을 상기하고, Positional encoding과 Resolution에 관한 추가적인 논의를 할 것이다.
Multi-head Self Attention layer(MSA)
Attention 기법은 Key, Value쌍으로 구성된 학습 가능한 Memory를 기반으로 한다. Query Vector($q \in \mathbb{R}^d$)는 k개의 Key Vector 집합($K \in \mathbb{R}^{k \times d}$)과 내적을 통해 매칭된다. 이 내적은 Softmax함수를 사용해 Scaling되고 정규화 되어 k개의 가중치를 생성한다. Attention의 출력은 k개의 Attention Value vector의 가중합($V \in \mathbb{R}^{k \times d}$)이다. N개의 Query vector ($Q \in \mathbb{R}^{N \times d}$)는 $N \times d$크기의 Output matrix를 생성한다.
\[\text{Attention}(Q, K, V) = \text{Softmax}(\frac{QK^T}{\sqrt{D}})V\]Self-attention layer는 Query, Key, Value가 N개의 Input vector($X \in \mathbb{R}^{N \times D}$)에서 생성된다.
\[Q = XW_Q \\ K = XW_K \\ V = XW_V\]Multi-head Self-attention layer는 h개의 attention “head”로 정의된다. (즉, Self-attention을 input에 h번 적용한다.) 각각의 head는 $N \times d$크기의 sequence를 제공하므로 $N \times dh$의 sequence가 발생하고, 이는 다시 Linear layer에 의해 $N \times D$로 Projection된다.
Transformer block for images
Transformer의 전체적인 구조는 위의 MSA Layer위에 FFN을 추가해야 한다. FFN은 2개의 Linear layer와 GeLU 활성화 함수로 구성되어 있다. 첫번째 Linear layer는 D차원에서 4D차원으로 입력을 확장시키고 두번째 layer는 다시 4D차원에서 D차원으로 입력을 축소시킨다. MSA와 FFN은 skip-connection에 의해 residual한 연산을 수행한 다음 layer normalization을 수행한다. transformer를 사용해 image를 처리하기 위해서 우리는 ViT모델에 따른다. ViT는 Image를 Sequence of input token으로써 처리하는 간단하고 섬세한 Architecture이다. 고정된 크기의 RGB Input image는 $16 \times 16$크기로 고정된 Patch N개로 나뉘고 각각의 Patch들은 linear layer로 Projection된다. Transforemr block은 위에 묘사되어 있듯이 patch embedding의 순서에 무관하다. Positional information은 고정되고 학습 가능한 Positional embedding을 통해 통합된다. Positional embedding은 첫 번째 transformer block 전에 더해진다.
The Class token
class token은 학습 가능한 Vector로 patch token 앞에 추가되어 transformer block과 linear layer를 통과한 후에 class를 예측하는데 사용된다. 이 class token은 NLP에서부터 상속되었고, Computer vision에서 class를 예측하기 위해 사용하던 전형적인 Pooling layer와는 다르다. 즉, transformer는 D차원의 N+1개의 Token을 처리하고 Class token만이 output을 예측하는데 사용된다. 이 architecture는 self-attention으로 하여금 정보를 patch token과 class token으로 뿌리도록 하고 supervision signal은 class embedding으로만 학습된다.
Fixing the positional encoding across resolution
이전 연구에서는 낮은 해상도로 학습하고 더 높은 해상도로 네트워크를 미세 조정하는 것이 바람직하다는 것을 알려준다. 이는 전체 훈련 과정을 가속화하고 기존 데이터 증강 방식과 함께하면 정확도를 향상시킬 수 있기 때문이다. 입력 이미지의 해상도를 높일 때, patch size는 동일하게 유지되므로 patch의 개수 N은 변경된다. transformer block과 class token의 구조로 인해 모델과 classifier는 더 많은 토큰을 처리하기 위해 수정될 필요가 없다. 반면에 Positional embedding은 N개가 존재하기 때문에 조정될 필요가 있다. ViT에서는 전체 resolution을 변경할 때 Positional encoding을 Interpolation했고, 이 방법이 이후의 fine-tuning단계에서도 효과적임을 증명했다.
4. Distillation through attention
이 Section에서 우리는 강력한 Image Classifier를 teacher 모델로써 사용할 수 있다고 가정한다. 교사 모델은 CNN일수도 있고, 여러 Classifier의 조합일수도 있다. 우리는 이 Teacher 모델을 활용하여 Transformer를 학습하는 방법에 대해 다룬다. Section 5에서 다룰 정확도와 Image 처리량간의 trade-off관계를 비교해 볼 때, CNN보다 Transformer를 사용하는 것이 더 효율적임을 알 수 있다. 이번 Section에서는 두 축의 distillation을 다룬다.
- Hard-distillation VS Soft-distillation
- Classical-distillation VS distillation token
Soft Distillation
Soft distillation은 Teacher model의 Softmax결과와 Student model의 Softmax결과의 KL Divergence를 최소화한다.
\[\mathcal{L}_{global} = (1-\lambda) \mathcal{L}_CE(\psi(Z_s), y) + \lambda \tau^2 KL(\psi(\frac{Z_s}{\tau}), \psi(\frac{Z_t}{\tau}))\]
- $Z_t$와 $Z_s$: teacher model과 Student model의 의 logit
- $\tau$: distillation temperature
- $\lambda$: KL Divergence와 Crossentropy간의 균형계수
- $\psi$: Softmax 함수
Hard-label Distillation
우리는 Teacher의 Output을 실제 Label로 간주하는 distillation의 변형을 소개한다.
\[\mathcal{L}_{global}^{hardDistill} = \frac{1}{2} \mathcal{L}_{CE}(\psi(Z_s), y) + \frac{1}{2} \mathcal{L}_{CE}(\psi(Z_s), y_t)\]
- $y_t = \underset{c}{\text{arg}\max} Z_t(C)$
주어진 image에 대해 teacher와 연관된 hard label은 data augmentation에 따라 바뀔 수 있다. 우리는 이것이 방식이 parameter-free하고 간단하지만 기존의 방식보다 더 낫다는 것을 발견했다. (teacher의 예측 $y_t$는 실제 label인 $y$와 동일한 역할을 한다.)
또한 Hard label방식은 Label sommthing방식을 통해 Soft label로 변환할 수 있다. 이때, 실제 label은 $1-\epsilon$의 확률을 갖고, $epsilon$은 나머지 class에게 할당된다. 우리는 이때, $\epsilon = 0.1$로 설정했다.
Distillation token
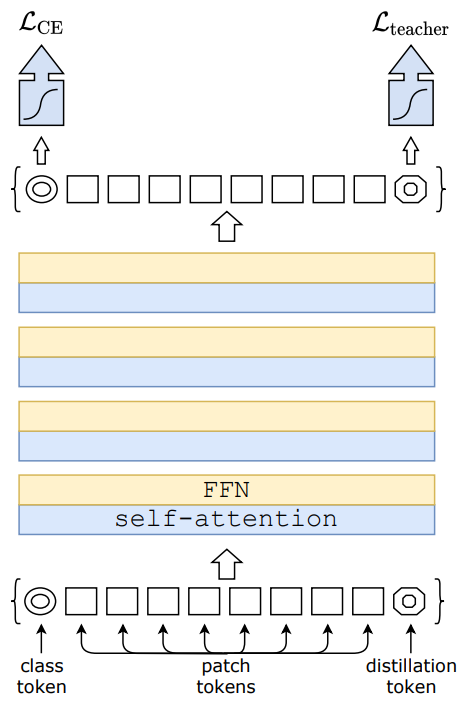
우리는 이제 위의 그림에서 소개된 distillation token에 초점을 맞춘다. 우리는 초기 embedding에 distillation token을 새로 추가하는데, 이 token은 class token과 유사하게 사용된다. 이 token의 target objective는 distillation component에 의해 정의되고, distillation embedding은 기존 dilstillation처럼 teacher의 출력으로부터 학습할 수 있어 class embedding과 상호 보완적인 관계를 갖는다.
이때, 흥미롭게도 학습된 distillation token은 서로 다른 vector로 수렴한다.(이 둘간의 평균 cosine유사도는 0.06이다) Class 및 distillation embedding이 각 layer에서 계산됨에 따라 점진적으로 유사해지고 마지막 layer에서는 유사도가 높아진다.(이 때의 cosine 유사도는 0.93이다.) 그러나 여전히 1보다 작다. 이는 두 토큰은 유사하지만 서로 다른 목표를 생성하도록 설계되었기 때문이다.우
우리는 동일한 target label과 연관된 class token을 단순히 추가한것과 비교했을 때, 우리의 distillation token이 어떤 정보를 model에 준다는 것을 증명했다. 비록 우리가 이 두 토큰을 random하고 독립적으로 초기화 하더라도 학습 중에 이들은 동일한 vector로 수렴하고 출력 embedding또한 거의 동일하다. 이 추가 class token은 분류 성능에 아무런 기여도 하지 않았다. 반면에 우리의 distillation전략은 기본 distillation baseline보다 상당한 성능 향상을 제공했다.
Fine-tuning with distillation
우리는 고해상도의 Fine-tuning과정에서도 true label과 teacher의 예측을 모두 사용한다. 우리는 동일한 target해상도를 가진 teacher를 사용하는데, 이는 일반적으로 낮은 해상도의 teacher로부터 얻어진다. 우리는 실제 label만 사용하는 것도 실험해 보았지만 이는 교사 모델의 이점을 감소시키며 낮은 성능을 초래했다.
Classification with our approach: joint classifier
test time에서 transformer가 생산한 class token과 distillation embedding은 모두 linear classifier와 연결되어 image의 label을 예측하는데 사용된다. 그러나 우리의 주요 방법은 이 두개의 분리된 head를 late fusion하는 방식이고, 이를 위해 두 classifier의 softmax 출력을 합산하여 예측한다.