[Paper Review] BEiT: BERT Pre-Training of Image Transformers
Source
Contents
0. Abstract
BEiT(Bidirectional Encoder representation from Image Transformers)는 자연어 처리(NLP) 분야에서 개발된 BERT의 아이디어를 확장하여 비전 트랜스포머(Vision Transformers)의 사전 학습(pretraining)을 위해 마스킹 이미지 모델링(masked image modeling) 작업을 제안한 모델이다.
BEiT 사전학습 과정에서 이미지는 두 가지 관점(과정)으로 처리된다.
- Image Patches(i.e. $16 \times 16$ pixels)
- Visual Tokens(i.e. discrete tokens)
구체적인 동작과정은 다음과 같다.
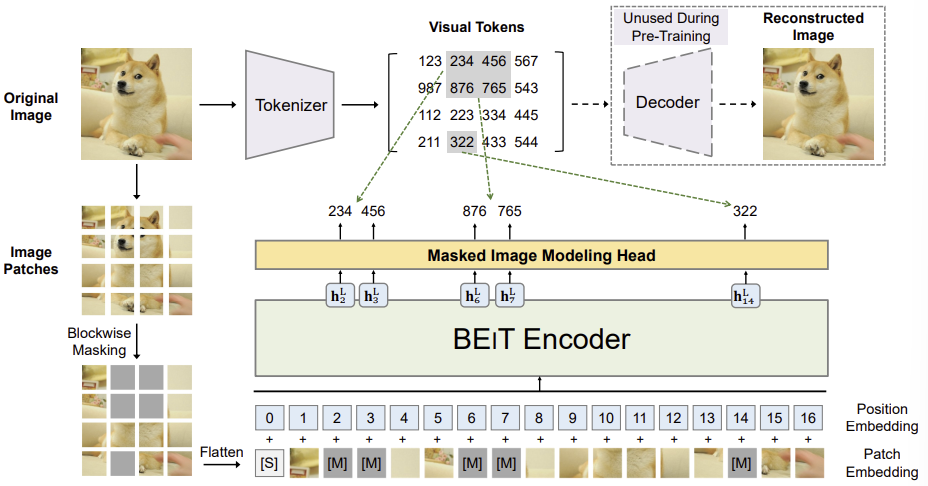
먼저 원본 이미지를 시각적 토큰(visual tokens)으로 변환하고, 일부 이미지 패치를 랜덤하게 마스킹하여 이를 백본 트랜스포머에 입력한다. 이때 사전 학습되는 BEiT의 목표는 손상된 이미지 패치 정보를 활용하여 원래의 시각적 토큰을 복원하는 것이다.
1. Introduction
Self-Supervised Pretraining의 필요성
Transformer는 컴퓨터 비전 분야에서 뛰어난 성능을 보여주었으나, Convolutional Neural Networks (CNN)보다 훨씬 더 많은 학습 데이터를 필요로 한다는 단점이 있다. 이를 해결하기 위해 Self-Supervised Pre-training이 대규모 이미지 데이터를 활용하는 유망한 솔루션으로 주목받고 있다. 비전 트랜스포머에 대해 여러 방식이 연구되었으며, 대표적으로 대조 학습(Contrastive Learning)과 Self-Distillation 등이 있다.
Previous Work(MLM)
한편, NLP 분야에서는 BERT가 큰 성공을 거두었으며, Masked Language Modeling (MLM) 작업이 그 핵심이다. 이 작업은 텍스트 내 일부 토큰을 랜덤하게 마스킹한 뒤, 손상된 텍스트를 Transformer로 인코딩하여 마스킹된 토큰을 복원하는 것이다. 이를 기반으로 우리는 Denoising Auto-encoding 아이디어를 비전 트랜스포머에 적용하고자 한다. 그러나 이미지는 언어와 달리 고유한 어려움이 있다.
- 이미지에는 BERT의 단어처럼 미리 정의된 어휘(vocabulary)가 없다.
- 단순히 Pixel 자체를 복원하는 경우에는 High-frequecy detail을 학습할 때에는 모델의 Capability를 낭비하게 된다.
Approaches
BERT에서부터 영감을 받은 BEiT라는 MIM(Masked Image Modeling)이라는 사전 학습 모델을 제안한다. MIM은 이미지에서 다음의 두 가지 관점을 사용한다
- Image Patches
- Random하게 Mask를 적용하고 Vision Transformer의 입력으로 사용
- Image Patches
- Visual Tokens
- Image를 VAE Encoder를 통해 Discrete하게 Tokenize하여 얻은 Latent Vectors
- Visual Tokens
Masked Patch는 Vision Transformer에 입력되어 원본 이미지의 Visual Token을 예측하게 된다.
2. Methods
2.1) Image Representation
2.1.1 Image Patch
2D Image를 Transformer에 입력하기 위해 Patch로 나눈다.
$x \in \mathbb{R}^{H \times W \times C} \rightarrow x^p \in \mathbb{R}^{N \times (P^2 \times C)}, \qquad N=\frac{HW}{P^2}$실험에서는 $224 \times 224$의 이미지를 $14 \times 14$의 Image Patch로 변환하였다. (i.e $P=16$)
2.1.2 Visual Token
- 이번에는 2D Image를 dVAE를 통해 Tokenize한다.
$x \in \mathbb{R}^{H \times W \times C} \rightarrow z \in \mathcal{V}^{h \times w}$- Image Token($z=[z_1, …, z_N]$)의 원소는 Visual Vocabulary($\begin{Bmatrix}1, …, \vert V \vert \end{Bmatrix}$) 중의 하나의 값을 갖는다.
- Discrete한 Latent Vector를 미분할 수 없기 때문에, Gumbel-Softmax를 사용하였고, 실험에서는 $|\mathcal{V}| = 8192$로 설정되었다.
2.2) Backbone Network: Image Transformer
- Transformer의 입력은 $\begin{Bmatrix}x_i^p \end{Bmatrix}^N_{i=1}$이다.
- 이를 패치 임베딩과 Positional Encoding을 적용하여 Transformer의 Encoder에 넣는다.
$H_0 = [e_{[s]}, Ex_i^p, …, Ex_N^p] + E_{pos}, \qquad E\in \mathbb{R}^{(P^2C)\times D}, E_{pos} \in \mathbb{R}^{N \times D}$- 마지막 Layer의 출력 $H^L$을 얻는다.
$H^L = [h^L_{[S]}, h^L_1, …, h^L_N]$
2.3) Pre-Training BEIT: Masked Image Modeling

(Masking 알고리즘)
\[\max \sum_{x \in \mathcal{D}} \mathbb{E}_\mathcal{M} [\sum_{i\in \mathcal{M}} \log p_{MIM}(z_i \vert x^\mathcal{M})]\]
- 40%의 Image Patche를 마스크한 다음, 이 마스크 patch를 $e_{[M]} \in \mathbb{R}^D$로 교체한다.
- Transformer의 Input으로는 Mask된 부분을 Mask Token으로 대체하고 모든 Patch를 Input으로 넣는다.
$\rightarrow x^{\mathcal{M}} = \begin{Bmatrix}x_i^p: i\notin \mathcal{M} \end{Bmatrix}^N_{i=1} \cup \begin{Bmatrix}e_{[M]}: i \in \mathcal{M}\end{Bmatrix}^N_{i=1}$- Output으로는 Mask된 부분의 Output부분만을 사용한다.
$\rightarrow \begin{Bmatrix}h_i^L: i \in \mathcal{M} \end{Bmatrix}^N_{i=1}$- Loss: Masking된 패치가 포함된 이미지($x^\mathcal{M}$)가 주어졌을 때, Masking된 부분이 Visual Token과 일치할 확률
※ $p_{MIM}(z_i \vert x^\mathcal{M}) = softmax(W_ch_i^L + b_c), \qquad W_c \in \mathbb{R}^{\mathcal{V} \times D}, b_c \in \mathbb{R}^{\vert \mathcal{V} \vert}$
$\quad \rightarrow$ Transformer의 Output을 1 ~ $\mathcal{V}$의 Visual Token에 대응시키는 것
2.4 dVAE 사전학습
(dVAE 사전학습 방법)
2.5 초기화
(Transformer의 안정된 학습을 위한 학습 Detail)
2.6 Downstream Task
(Fine-tuning방법)