4. Authentication
Entity Authentication
1. Identification
내가 누구인지 증명해야할 필요가 있을 때 가 있다.
1) Attacks against Identification
공격 종류
- Impersonation(사칭, 도용)
- Replay(이전 인증 메시지를 재사용)
- Interleaving(인증 세션 교차 사용)
2) Type of Identification
Password based
일반적인 password는 entropy가 낮아 추측이 쉽다는 문제가 있다. 즉, 고정된 패스워드를 사용할 경우 ⅰ) 도청시, ⅱ) 패스워드 테이블이 유출될 경우 위험할 수 있다.
이를 방지하기 위해 다음과 같은 방식들을 사용할 수 있다.
- Hashed Password
- 사용자의 Password를 Hashing한 후 서버에 저장하는 방식 (해시함수의 단 방향성 이용)
$\rightarrow$ 사용자들이 많이 사용하는 password나 복잡하지 않은 암호의 경우 공격자가 쉽게 유추할 수 있음(dictionary attack)
- Salted Password
- Password + Salt를 Hashing한 후 서버에 저장하는 방식 (Salt는 사용자 별 고유의 Salt를 갖도록 함)
$\rightarrow$ Salt는 비밀 값이 아니기 때문에, 공격이 불가능해지는 것이 아니라 여전히 비싸게 만드는 방식이다.(dictionary attack 가능)
- One-Time Password(OTP)
- 한 번 쓰고 버리는 비밀번호(매번 다른 숫자가 나오고, 그 순간에만 유효)
- Synchronized OTP
- 사용자와 서버가 Seed를 공유한 후, 같은 기준(시간, 이벤트)으로 비밀번호를 생성
(e.g. 시간 동기화 방식: $sk = H(seed, T)$)
- Non-Synchronized OTP
- 사용자가 $W_0$을 n번 hash한 값 $W_n$을 전송 후 저장.
- 이후 사용자가 $W_{n-1}$을 보내면 서버는 $H(W_{n-1}) = W_n$이 맞는지 확인하고 $W_{n-1}$을 저장
- Smart OTP
Symmetric Key based
Timestamp 기반
ⅰ) A가 B에게 현재 시간 $t_A \Vert B$ 를 공유키 K로 암호화 하여 전송
ⅱ) B는 공유키 K로 이를 복호화 하여 A를 인증
장점) Replay Attack을 막을 수 있음난수 기반
ⅰ) B가 A에게 난수 $r_B$를 전달(Challenge, 계속 달라짐)
ⅱ) A는 $r_B \Vert B$를 공유키 K로 암호화하여 다시 전달
ⅲ) B는 이를 공유키로 복호화 하여 $r_B$가 맞는지 확인 후 A를 인증
장점) 시간 동기화, Threshold가 필요 없음난수 기반(상호인증)
ⅰ) B가 A에게 난수 $r_B$를 전달
ⅱ) A도 난수 $r_A$를 생성한 후 $r_A \Vert r_B \Vert B$를 공유키 K로 암호화 하여 전달
ⅲ) B가 이를 공유키로 복호화 하여 A를 인증한 후에, 다시 A에게 $r_A \Vert r_B$를 암호화하여 전달
ⅳ) A는 이를 복호화하여 B를 인증※ 여기에 추가적으로 MAC을 통해 무결성을 보장할 수 있음
Public Key based
Timestamp 기반
ⅰ) A가 B에게 자신의 인증서를 포함해 $cert_A \Vert t_A \Vert B \Vert S_A(t_A, B)$를 비밀키로 서명($S_A$)하여 전달
ⅱ) B는 A의 Public Key로 이를 검증난수 기반(서명 이용 방식)
ⅰ) B가 A에게 난수 $r_B$를 전달
ⅱ) A가 B에게 자신의 인증서를 포함해 $cert_A \Vert r_A \Vert B \Vert S_A(r_A, r_B, B)$를 비밀키로 서명($S_A$)하여 전달
ⅲ) B는 A의 Public Key로 이를 검증
특징) $r_A$가 있는 이유는, 만약 B가 악의적으로 $r_B$에 의미 있는 값을 보내면 A는 자신이 동의하지 않는 일에 Sign한 것이 되기 때문이다.난수 기반(공개키 이용 방식)
ⅰ) B가 난수 $r_B$와 A의 Public Key($pk_A$)를 활용해 $h(r_B) \Vert B \Vert E_{pk_A}(r_B, B)$를 A에게 전달
ⅱ) A는 자신의 Secret Key로 이를 복호화 하여 난수 $r_B$를 B에게 전달
ⅲ) B는 이를 검증
특징) $h(r_B)$가 있는 이유는, B가 악의적으로 자기가 원하는 값에 대한 복호화 값을 얻어볼 수 있기 때문이다.(마치 A를 Decryption Oracle처럼 사용 가능)
따라서, 어떤 난수 $r_B$에 대한 복호화 값을 이미 알고 있음을 증명하기 위해서이다.상호인증
ⅰ) A가 B에게 난수$(r_A)$를 B의 Public Key로 암호화하여 $E_{pk_B}(r_A, A)$를 전달
ⅱ) B가 A에게 난수$(r_B)$를 A의 Public Key로 암호화하여 $E_{pk_A}(r_A, r_B)$를 전달
ⅲ) A가 B에게 B의 난수$(r_B)$를 전달
2. Biometric Recognition
1) 구성 요소
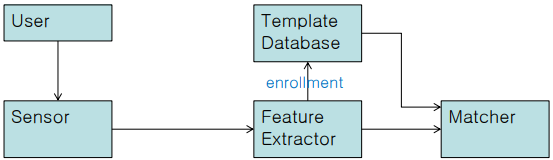
- Sensor: 지문 스캐너, 얼굴 카메라, 마이크 등 신호 채집 장치
- Feature Extractor: 센서의 원본 데이터를 정제하여 feature만 뽑아냄
- Template Database: 사용자들의 생체 Feature template 저장
- Matcher: 입력된 특징과 유사도 점수 계산
인증방식
- Verification(1:1)
- DB에 저장된 x의 템플릿과만 비교하여 matching score가 threshold보다 높으면 인증
- Identification(1:n)
- DB에 있는 모든 사용자와 비교해 가장 점수가 높은 사람이 threshold보다 높을 경우 인증
2) 특징
- (Uniqueness) Inter-user similarity가 작아야 함
- False Match를 줄일 수 있음
- (Uniqueness) Inter-user similarity가 작아야 함
- (Permanence) Intra-user variation이 작아야 함
- False non-match를 줄일 수 있음
- (Permanence) Intra-user variation이 작아야 함
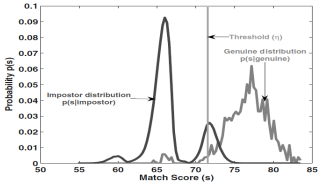
FAR & FRR
$x_{nt}$: n번째 사람의 t번째 샘플
\(I_1: (x_{11}, x_{12}, ..., x_{1t}) \\ I_2: (x_{21}, x_{22}, ..., x_{2t}) \\ ... \\ I_n: (x_{n1}, x_{n2}, ..., x_{nt})\)
FAR과 FRR의 trade off 관계를 고려해 적절한 threshold를
설정 해야한다.
- Genuine score: 같은 사람의 두 샘플을 비교하는 경우의 수
- ${t \choose 2} \times n$
- Impostor score: 서로 다른 사람의 샘플끼리 비교하는 경우의 수
- $t^2 \times {n \choose 2}$
- FAR(False Accept Rate): 남을 나라고 잘못 인증하는 경우
- $\text{FAR}(\eta) = p(s \geq \eta \;\vert\; \text{impostor})$ (Imposter score의 PDF)
- FRR(False Reject Rate) 나를 나라고 인증하지 못하는 경우
- $\text{FRR}(\eta) = p(s \leq \eta \;\vert\; \text{genuine})$ (Genuine score의 PDF)
공격 모델
유형 특징 문제 발생 Sheep 이상적 사용자 거의 문제 없음 Goats 본인 매칭이 불안정 (intra-user ↑) FRR ↑ (본인을 거절) Lambs 다른 사람과 비슷함 (inter-user ↑) FAR ↑ (타인을 허용) Wolves 타인을 속일 수 있음 보안적 위협 ※ 직업군별로 sheep이 될 수 있는 biometric trait이 다르기 때문에 trait의 적절한 선택이 필요하다.
3) Fingerprint Recognition
지문은 크게 Ridge(선)와 Valley(골) 패턴으로 구성되어 있다.
이러한 지문을 찍는 방식은 ⅰ) Rolled, ⅱ) Plain, ⅲ) Latent(잠재 지문) 등 으로 나뉘게 된다. 이때, 각각의 지문에 대해 정확하게 인식하도록 하는 것이 중요하다.
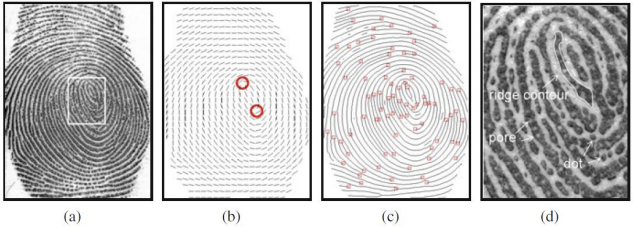
Level
(왼쪽부터 (a) 원본, (b) level 1, (c) level 2, (d) level 3)
지문은 수집된 해상도에 따라 level 3 feature 까지 추출할 수 있다.
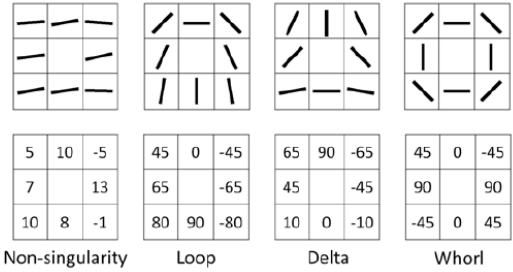
- Level 1: 다음 점들의 패턴을 추출할 수 있고, 이를 기준으로 Plain arch, Tented arch, Left/right loop, Whorl, Twin loop로 분류할 수 있다.
- (a) Loop: ridge가 돌아 나가는 형태
- (b) Delta: 세모 형태로 ridge가 모이는 점
- (+) Whorl: Loop 2개가 모여 ridge가 하나의 점으로 모이는 형태
- (+) Non-Singularity: ridge나 delta가 없을 때
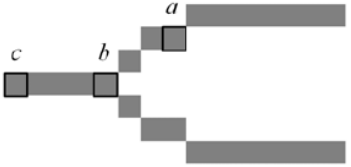
- Level 2: Level2에서는 다음 특징을 갖는 점들의 위치와 방향을 활용할 수 있다.
- Ridge ending: Ridge가 끝나는 지점
- Ridge bifurcation: Ridge가 갈라지는 지점
- Level 3: 1000dpi 이상의 고해상도 장비를 통해 관찰 가능
보통 인증은 level 1, 2를 같이 활용하는 경우가 많고, 경우에 따라 level 3을 활용하기도 한다.
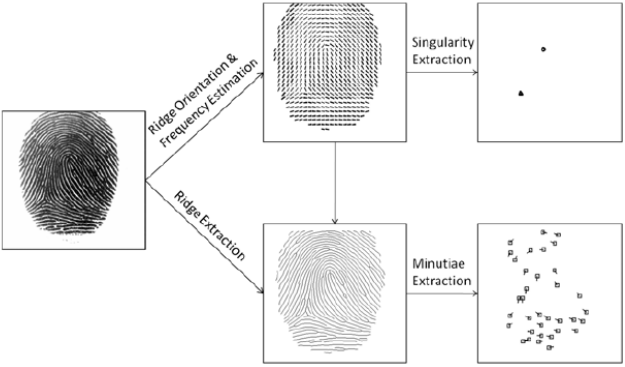
Pipeline
ⅰ) Ridge Orientation & Frequency Estimation
\[\Downarrow\]
$\quad$: 부분 이미지에 대해 DFT(Discrete Fourier Transform)을 적용하여 방향과 freq 추출
$\quad$: Smoothing 과정을 거처 방향 보정
singularity filter Poincare index ⅱ) Singularity Extraction
\[\Downarrow\]
$\quad$: (Point) Poincare index등을 활용하여 singularity를 판단한다.(0: non, $\frac{1}{2}$: loop, $-\frac{1}{2}$ delta, 1: whorl)
$\quad$: (Direction) Ridge의 방향(O)과 Reference(loop, delta)의 방향(RO)을 이용해 loop와 delta의 방향을 설정(e.g. $D_{loop} = \tan^{-1} (\frac{\sum_W \sin2(O(x, y) - RO(x, y))}{\sum_W \cos2(O(x, y) - RO(x, y))})$)
ⅲ) Ridge Extraction
\[\Downarrow\]
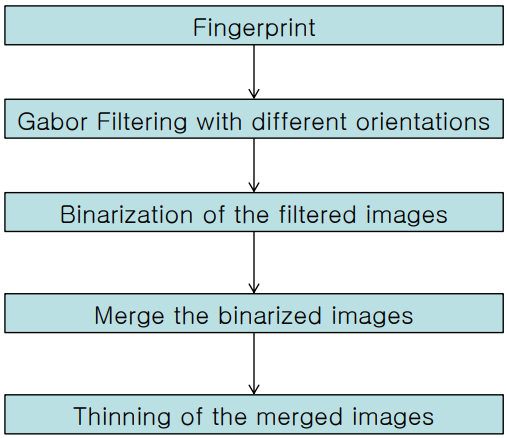
$\quad$ (Gabor Filtering): 다양한 방향의 필터를 사용하여 융선을 선명하게 만든다.
$\quad$ (Binarization): 필터링된 이미지를 흑백(0과 1)으로 변환한다.
$\quad$ (Merge): 이진화된 이미지들을 하나로 합친다.
$\quad$ (Thining): 융선의 두께를 1픽셀로 얇게 만들어 뼈대만 남긴다.
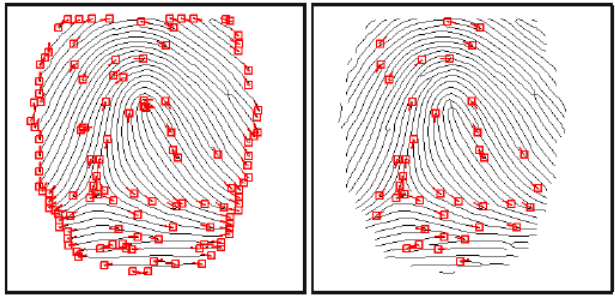
ⅳ) Minutiae Extraction
\[\Downarrow\]
$\quad$ (Minutiae Detection): bifurcation과 ending을 찾아 “표시”한다.
$\quad$ (Calculate Direction): bifurcation과 ending의 방향을 계산한다.
$\quad$ (Remove): 테두리부분같은 spurious minutiae를 제거한다.
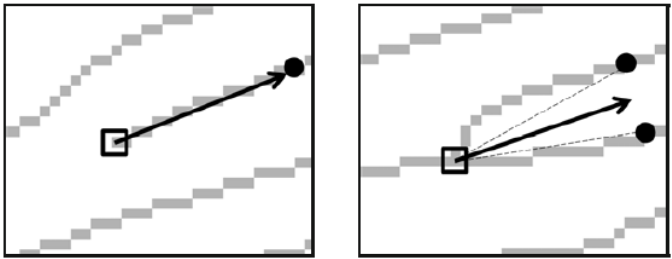
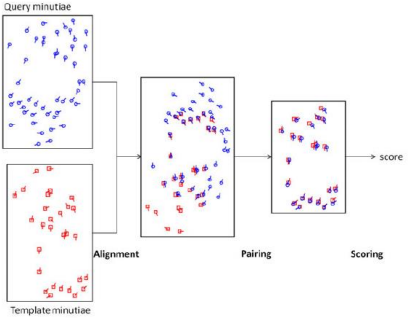
ⅴ) Matching
$\quad$ (Alignment): bifurcation과 ending을 찾아 표시한다.
$\quad$ (Pairing): bifurcation과 ending의 방향을 계산한다.
$\quad$ (Scoring): 테두리부분같은 spurious minutiae를 제거한다.