4. SQL Basic(2)
DML
앞서 DML의 구조와 내용에 대해 간단히 찍먹해 보았다면, 이제 좀더 다양한 키워드들과 자세한 내용을 알아보도록 하자.
| 문법 작성 순서 | 컴퓨터의 해석 순서 | |
|---|---|---|
| 1 | SELECT | FROM |
| 2 | FROM | WHERE |
| 3 | WHERE | GROUP BY |
| 4 | GROUP BY | HAVING |
| 5 | HAVING | SELECT |
| 6 | ORDER BY | ORDER BY |
위의 표는 실제 Select문을 입력할 때 작성하는 쿼리의 순서와 동작하는 순서이다.
Query 해석 순서(유효범위)
앞서 SQL의 특징에서 설명 했듯이 SQL은 쿼리의 순서에 상관없이 실행되는 완벽한 declarative언어이다.
하지만 이것은 명령의 해석 결과 순서는 상관 없다는 뜻이지 해석하는데에 순서가 없다는 뜻은 아니다.
예를 들어 아래와 영어 문장을 생각해 보자
- 해석결과
- 순서에 상관없이 3개의 Table을 연결하라.
- 해석순서
- 주어 - 목적어 - 동사
이와 같은 이유로 정의에 대한 유효 범위가 발생한다. 다음과 같은 sql문을 보자.
해당 sql문을 순서대로 해석해보면 WHERE절에서 course에는 CID라는 Attribute는 존재하지 않는다는 것을 알 것이다.
즉, CID는 마지막에 해석되는 SELECT절에서 정의해 준 것이기 때문이다.
FROM
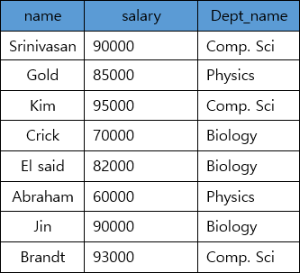
FROM절은 앞으로 사용할 Relation을 정하는 곳이다. 이때 우리는 하나의 Relation만 가져오는 것이 아니라 여러개의 Relation을 합쳐 사용하게 된다.
이때 합치는 방법은 다음과 같이 매우 다양하다.
1. Catesian Product
두 Relation의 가능한 모든 조합을 선택하는 것
2. Join
특정한 조건에 따라 Table을 연결하는 것
1) Join Option(Equi Join)
위의 sql문과 같이 “
=“를 이용하여 조건을 설정하여 Table을 합치는 방법을 EQUI JOIN이라고 한다.위의 EQUI JOIN은 다음과 같이 3가지 Keyword를 통해 표현할 수 있다.
NATURAL JOIN- Attribute Name이 같은 것을 자동으로 EQUI JOIN
JOIN USING()- USING()에 사용된 Attribute를 사용하여 EQUI JOIN
JOIN ON()- ON()에 사용된 Condition에 맞도록 JOIN
JOIN-ON
위의 설명을 보면 알 수 있듯이
JOIN ON에는 꼭 EQUI JOIN만 사용되는 것이 아닌 다양한 Condition을 설정해 줄 수 있다.따라서 위의 3가지 예시의 결과는 모두 똑같이 출력되지 않는데, 이는
JOIN ON은 EQUI JOIN을 위해 만들어진 Keyword가 아니기 때문이다.즉,
JOIN ON의 결과 Attribute의 개수가 하나 더 많은 Relation이 반환되게 된다.
EQUI-JOIN= idJOIN ON= R1.id, R2.id

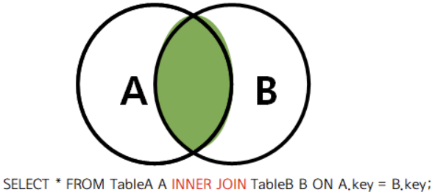
2) INER JOIN vs OUTER JOIN
INNER JOIN (= JOIN)
위에서 배운 모든 JOIN은 INNER JOIN이다.
(INNER는 생략이 가능하다)즉, 왼쪽뿐만 아니라 오른쪽의 어떠한 Relation도 자신의 Tuple을 모두 Return할 필요 없다.
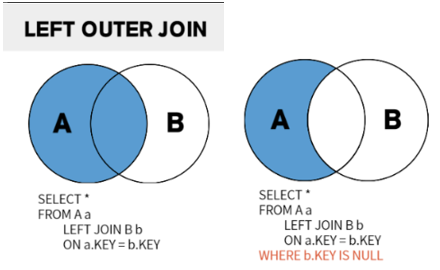
LEFT OUTER JOIN (=LEFT JOIN)
LEFT OUTER JOIN은 왼쪽의 Relation의 모든 Tuple들은 반드시 다 표시해야 한다. (OUTER는 생략이 가능하다.)
즉, 다음과 같은 과정을 통해 얻을 수 있다.
- A의 모든 Tuple들을 적는다.
- 이 Tuple들에 맞춰 B의 Tuple을 적는다.
(이때, 이에 맞는 A의 값이 중복선택되는 경우 한번 더 적어 표현한다.)이 결과 A의 조건을 만족하지 못하는 B의 Tuple들은 Null값으로 채워져 나온다.
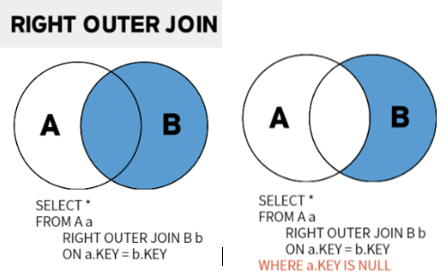
RIGHT OUTER JOIN (=RIGHT JOIN)
RIGHT OUTER JOIN은 오른쪽의 Relation의 모든 Tuple들은 반드시 다 표시해야 한다. (OUTER는 생략이 가능하다.)
즉, 다음과 같은 과정을 통해 얻을 수 있다.
- B의 모든 Tuple들을 적는다.
- 이 Tuple들에 맞춰 A의 Tuple을 적는다.
(이때, 이에 맞는 B의 값이 중복선택되는 경우 한번 더 적어 표현한다.)이 결과 B의 조건을 만족하지 못하는 A의 Tuple들은 Null값으로 채워져 나온다.
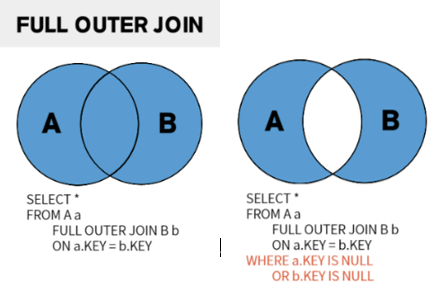
FULL OUTER JOIN
Full Outer Join은 조건에 맞게 두 Relation을 합치되, 오른쪽과 왼쪽의 Relation중 누락되는 데이터가 없도록 전부 출력하는 Join연산이다.
이는 Catesian Product와 헷갈릴 수 있지만 Full Outer Join은 특정 조건을 검사하므로 이 Catesian Product안에 속한 집합이나오게 된다.
My SQL은 FULL OUTER JOIN을 지원하지 않는다.
따라서 FULL OUTER JOIN을 구현하기 위해서는 UNION연산을 활용해야한다.
WHERE
1. NULL
SQL에는
TRUE,FALSE,NULL의 3가지 논리 상태가 존재한다.1) 산술연산자 & 비교연산자
산술연산자 & 비교연산자에 대해서는 모두 NULL을 반환한다.
- 산술연산자
NULL + a→NULL- 비교연산자
NULL > a→NULLNULL = a→NULLNULL != a→NULL2) 논리연산자
확실하지 않은 연산에 대해서는 모두 NULL을 반환한다.
2. ALL & SOME
1) ALL vs SOME
1. 연산순서
ALL: Subquery계산 → Main Query계산SOME: Subquery계산 → Main Query계산2. 연산방법
ALL- MainQuery의 Tuple을 일일이 SubQuery의 결과와 비교하여 모든 Tuple이
TRUE를 반환하는지 확인
(AND연산으로 결과들을 합쳐TRUE가 나오는지 확인)
SOME- MainQuery의 Tuple을 일일이 SubQuery의 결과와 비교하여 모든 Tuple이
TRUE를 반환하는지 확인
(OR연산으로 결과들을 합쳐TRUE가 나오는지 확인)

2) 문자열 비교
LIKE %: 임의의 문자가 여러개 들어갈 수 있음
LIKE _, LIKE ?: 임의의 문자가 한개 들어갈 수 있음예시
3. IN & EXISTS
1) IN vs EXISTS
1. 연산 순서
IN: Subquery계산 → Main Query계산EXISTS: MainQuery계산 → Subquery계산2. 연산 방법
IN: MainQuery의 Tuple을 일일이 SubQuery의 결과와 비교하여 True를 반환하는 Tuple이 있는지 확인EXISTS: MainQuery를 계산하며 각 Tuple을 Subquery에 대입했을 때, Subquery의 결과가 존재하는지 확인즉,
EXISTS는 공집합인지에 대한 여부만 파악하기 때문에IN보다 연산수가 더 적고 따라서 더 빠르다.
2) ANTI JOIN & SEMI JOIN
ANTI JOIN
SubQuery에는 없는 메인 쿼리 결과 데이터만 추출하는 것
`NOT IN`이나 `NOT EXISTS` 연산자를 통해서 구현 가능하다.
(
NULL값의 존재로 인해 의미론 적으로는ANTI JOIN을 쓸 때,IN이나NOT IN을 쓰는 것이 맞다.)SEMI JOIN
SubQuery에 있는 메인 쿼리 결과 데이터만 추출하는 것
`IN`이나 `EXISTS` 연산자를 통해서 구현 가능하다.
SELECT
1. Aggregate Function
SELECT문에서는 다음과 같은 함수들을 사용할 수 있다.
- DISTINCT : 중복을 제거하여 Return
- ALL(생략가능) : 중복제거없이 Return
- 산술식 : 산술식을 적용하여 Return
이때, 결과 값으로 단일값을 내놓는 함수들이 있는데 이러한 함수들을 Aggregate Function이라고 한다.
1) Function
- COUNT()
- SUM()
- MAX()
- MIN()
- AVG()
2) GROUP BY & HAVING
GROUP BY
- 목적
- Aggregate Function을 Relation 전체가 아닌 Group별로 적용하기 위해서 사용
- 주의점
- Group By를 사용한 경우 반드시 SELECT에서 Aggregate Function을 사용해 주어야 한다.
HAVING
- 목적
- WHERE절은 Group By이전에 해석되기 때문에 Group으로 나눈 후에는 Group의 조건을 설정할 수 없다.
- 즉, 골라내고 싶은 Group의 조건이 있을때 사용한다.
- 주의점
- Group By가 있을 때만 사용 가능하다.
SELECT
- 목적
- Project의 역할을 한다.
- 즉, 모든 선택을 마친 뒤 결과로 보여줄 Attribute를 고르기 위해 사용한다.
- 주의점
- 만약 Aggregate함수를 사용하였고 이때 중복을 제거해야 하는 경우
DISTINCTKeyword를 잘 사용해 주자
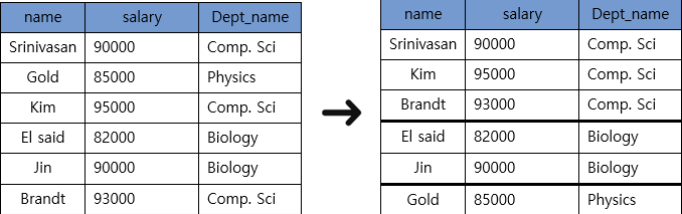
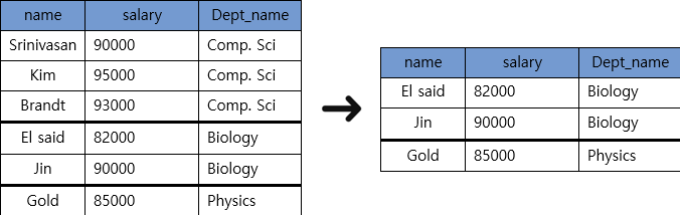
3) Aggregate 함수의 NULL처리
count함수가 아닐 경우
- 모두 null일 경우: 결과도 null
- null이 아닌 것이 있는 경우: null을 제외한 나머지에 대해 함수 수행
count함수의 경우
count(*)의 경우 (null을 제외하지 않고 셈)
- 모두 null일 경우: Row의 수
- null이 있을 경우: Row의 수
count(A)의 경우 (0부터 null을 제외하고 셈)
- 모두 null일 경우: 결과는 0
- null이 있을 경우: null을 제외하고 셈
2. Order By
- 목적
- 모든 Instance선택을 마치고 결과Relation을 출력할 때, 정렬된 결과를 보고 싶은 경우 사용한다.
사용법(오름차순, 내림차순)
ORDER BY A ASC: A를 기준으로 오름차순으로 정렬하여 출력한다. (이 경우 asc는 생략가능)
ORDER BY A DESC: A를 기준으로 내림차순으로 정렬하여 출력한다.- 옵션(정렬기준 여러개 설정)
ORDER BY A, B DESC, c: 이런 방식으로 정렬기준의 우선 순위를 설정할 수 있다. (A,C 오름차순, B내림차순)
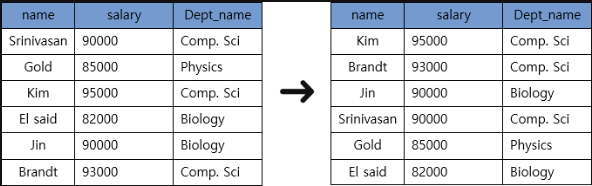
RELATION
EXCEPT UNION INTERSECT
ASSERTION, TRIGER, VIEW
1. ASSERTION
: Relation들이 만족해야 하는 조건 설정 
2. TRIGER
: insert나 update시 조건 검사 
3. VIEW
가상의 Table 생성 
DML로 Algebra표현 하기
SQL에 대한 기본적인 구조와 문법은 알았으니, 이제 DML을 활용해 다음과 같은 Algebra는 어떻게 표현할 수 있을 지 생각해 보자.
1. Join
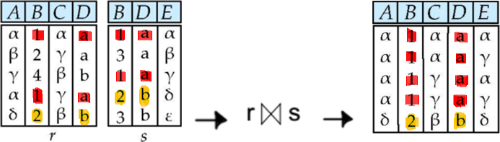
위와 같이 join은 두 Table에서 Attribute의 이름과 그 Instance가 동일한 값을 가질때만 해당 Tuple을 서로 연결하는 Algebra이다.
1) Where절 활용
우선,
rxs에서 이름이 같은 Attribute에 대해 같은 값을 가지고 있는 Tuple들을 일일이 Select해주는 방법이 있다.
(주의)
- DML은 실제 Algebra와는 달리 기본적으로
r.B와s.B를 같은 Attribute로 보지 않는다.- 즉,
B와D같이 Join하는 Attribute는SELECT절에서 r또는 s Table중에서 하나만 골라 주어야 한다.
(만약 고르지 않을 경우r.B,s.B,r.D,s.D를 모두 갖는 Table을 얻게 될 것이다.)
2) natural Join키워드 활용
그 다음으로
NATURAL JOIN키워드를 활용하는 방법이 있다.
위와 같이
NATURAL JOIN은 이름이 겹치는 Attribute들을 알아서 골라 연결한다.(참고)
이 때, 1번방법과 달리 Attribute를 연결할 때 알아서 같은 이름의 Attribute중 하나만을 골라 연결하기 때문에 따로 신경쓰지 않아도 된다.
3) Join r using(A)키워드
마지막으로
Join키워드를 사용하는 방법이 있다.
본래
NATURAL JOIN은 이름이 같기만 한다면 자동으로 연결했지만,
r JOIN s USING(A)는 USING에 사용된 Attribute만을 활용하여 이름이 같을 경우 연결하게 된다.
4) Join할 때 주의점
- where 절
where을 활용해서 조건에 맞는 Tuple들을 뽑아내어 만든 Relation의 경우 중복이 발생할 가능성이 높다.
따라서, 이를 잘 파악한 후에distinct키워드나 다른 조건을 활용하여 중복을 없애자.
- natural join
natural join의 특성상 원하지 않는 Attribute들의 Join이 발생 할 수 있다. 따라서 다음과 같은 상황을 주의하자.
두 테이블에서 이름이 같은 Attribute가 우연히 있을 경우
(ex. 이름이 같지만 각 Table에서 뜻을 다르게 사용하고 있을 때)세개 이상의 Table을 연결할 때
(ex. a, b, c의 Relation에서 a와 b를 ID로 Join하고 b에 c를 course_id로 Join하고 싶을 때)
- 이 경우 Non-Procedural한 Sql의 특성상 a와 b를 join한 후에 그것을 c와 join하는 것이 아니다.
- 즉, a와 c에 같은 이름의 Attribute가 있을 경우 a와 c도 join되어 a-b-c 전체가 join이 되어 버린다.
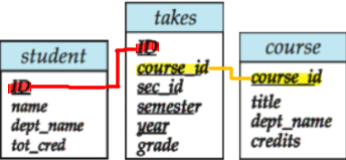
3개를 NATURAL JOIN할 때 발생할 수 있는 문제 예시
아래와 같은 Relation이 3개가 있다고 할 때, 어떤 학생이 어떤 과목을 수강했고, 그 과목의 강의명을 보고싶다고 하자.
즉, 우리는 student와 takes를 ID로 join하고, takes와 course를 course_id로 join해야 한다.
- 1번방법(잘못됨)
이 문장은
student와takes를 join한 후에 그 결과를course와 join하는 것이 아닌takes와student, 그리고course모두 join 하라는 명령이다.
- 2번방법(가능함)
- 3번방법(가능함)
2. Rename
1) Attribute
select절에서
as를 사용할 경우결과로 만들어 내는 Relation의 Attribute가 Rename되어 출력된다.
(주의)
이 경우, 실제 Table이 변경되는 것이 아니라 표현 방법만 변경 되는 것이다.
2) Table
from절에서
as를 사용할 경우 Table을 Rename하여 사용할 수 있다.
(참고)
자신의 Relation에서의 데이터와 비교가 필요할 경우가 있다.
이 때 Relation을 Rename하여 활용하면 쉽게 self join을 구현할 수 있고, 자신의 Relation과 비교가 가능해진다.
3) Attribute & Table
from절에서
as와 함께 괄호로 Attribute name을 순서대로 입력해 주면 Table과 그 Attribute 모두 Rename할 수 있다.