9. Indexing(2)
Index는 내가 원하는 Record의 위치를 가리키고있는 date Structure를 말한다.
이 Index는 다음과 같은 Record로 구성된 하나의 File이다 | | | |—|—| |Search-Key| Pointer|
여기서 Search key는 찾을 대상을 구분하는 역할을 하고
Pointer는 해당 Record의 실제 위치를 가리키고 있다.
이를 RDBMS에서 Relation에 적용하면 각각의 Attribute는 Search Key의 역할을 할 수 있다.
따라서 이를 활용해 Index File을 만들고 이를 활용하면 데이터를 읽어오는 속도를 매우 높일 수 있다.
물론, Insertion이나 Deletion과 같은 DataBase의 Update에 있어 Index File도 추가적으로 Update해주어야 하므로 관리 비용이 존재하지만,
Data Base의 주된 사용 목적은 Search이기 때문에 효율적인 RDBMS를 위해서는 Index를 적극적으로 활용해야한다.
index 평가요소
- Access Time
- Data를 얼마나 빨리 찾을 수 있는지
- Insertion Time
- Data를 Insertion할 때 걸리는 시간
- Deletion Time
- Data를 Deletion할 때 걸리는 시간
- Space Overhead
- Index File의 크기를 얼마나 줄였는지
Index
1. Index Type
1) Primary VS Secondary
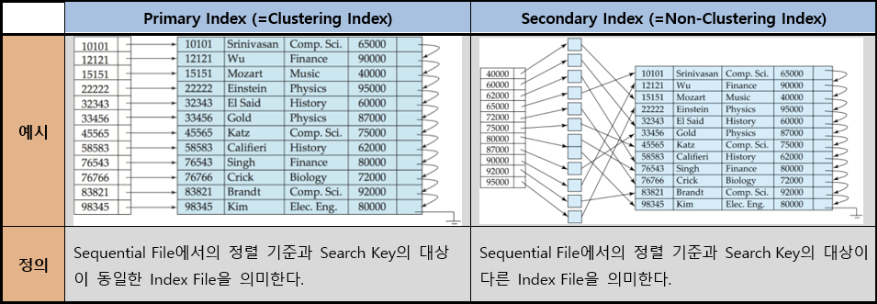
(data file=sequential file)
| | Primary Index | Secondary Index | | —- |:————-:|:—————:| | 정의 | 처음부터 정렬이 되어있는 Attribute에 대한 Index File | 정렬되어 있지 않은 Attribute에 대한 Index File | | 값 | Block의 위치 | Block의 포인터 배열의 위치 | | 개수 | Table당 한 개 | Table당 여러 개 | | Select속도 | 빠름 | 느림 | | I/M/D속도 | 느림 | 빠름 | —
(I:Insert, M:Modify, D:Delete)
My SQL의 경우 Primary Key를 지정해주면 자동으로 해당 Attribute를 Primary Index로 하는 Index File을 생성한다.
Sequential Scan시 I/O Complexity
- Primary Index의 경우
- Data File과 정렬 순서가 일치하므로 Sparse Index를 활용해
$O(\frac{N}{B})$의 I/O Complexity 가 가능하다.
- Secondary Index의 경우
- Data File과 정렬 순서가 다르기 때문에 Sparse Index를 활용할 수 없고
$O(N)$의 I/O Complexity 가 발생하게 된다.
2) Dense VS Sparse
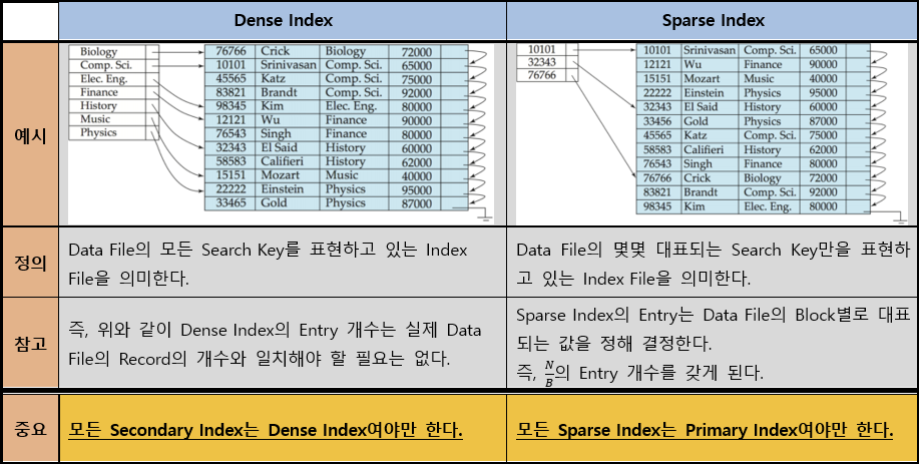
(역은 성립하지 않는다.)
Sparse Index를 사용할 경우 Index File의 크기를 효과적으로 줄일 수 있다.
이는, Index File조차도 Memory에 올라갈 수 없을 정도로 클 때 해결책이 될 수 있다.Multi Level Index
Sparse Index File을 층층이 쌓아 Multi Level Index File을 만들 수 있다.
(Inner Index: Primary Index of Data File)
(Outer Index: Sparse Index of Primary Index)이때, 각 i번째 층은 $\frac{N(i-1)}{B(i-1)}$개의 Entry를 갖게된다.
즉, 각 층마다 Block의 수를 $\frac{1}{B}$씩 줄일 수 있게되고,
이를 통해 Data에 접근하기 위해 Search할 Block의 수를 효과적으로 줄일 수 있다.4. Multi Level Index의 단점
Search만 하는 DB의 경우 Multi Level Index는 단점이 없는 구조가 되지만 Update가 발생할 경우 문제가 발생하게 된다.
Data를 Delete/Insert할 때, Free Space가 많은 Data Block이 발생하게 된다.
즉, 대표값을 통해 Block Access횟수를 줄인다는 Sparse Index의 장점이 사라지게 된다.
따라서 주기적인 Reorganization이 필요하다.
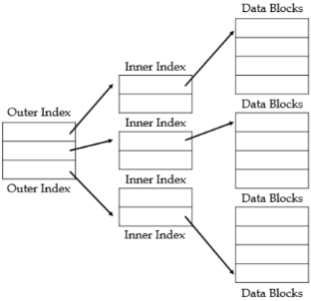
2. Index Algorithm Type
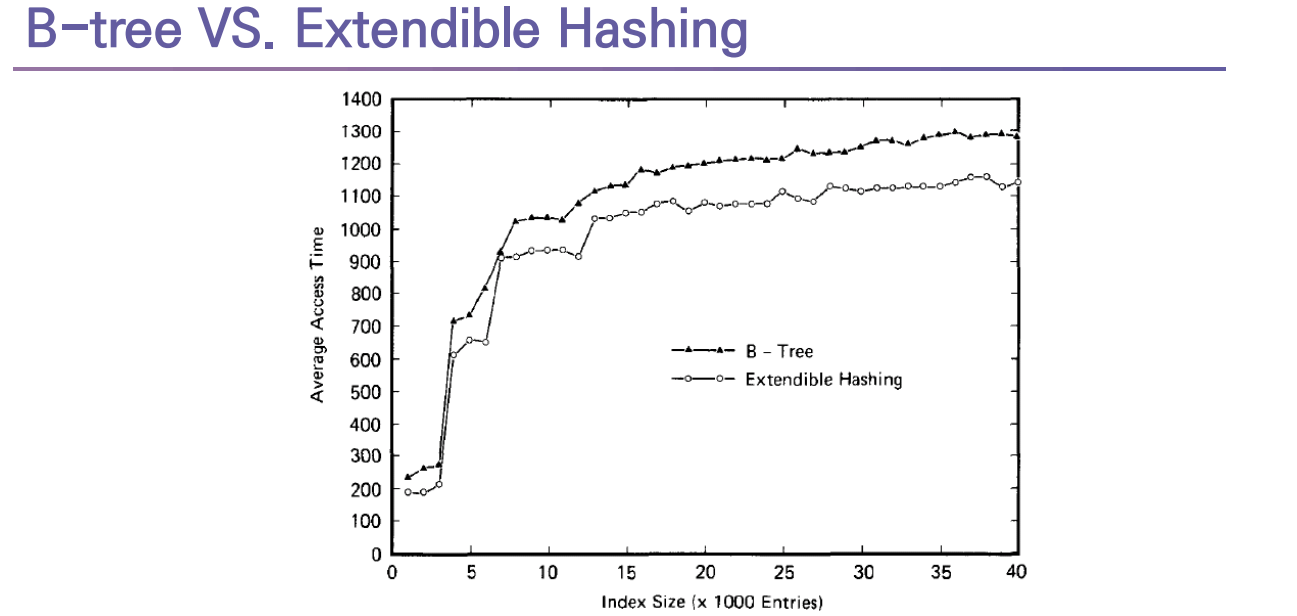
이제 Index File을 설계하는 방법들에 대해서 간단하게 살펴보도록 하자
1) Hash
2) B+ Tree Index
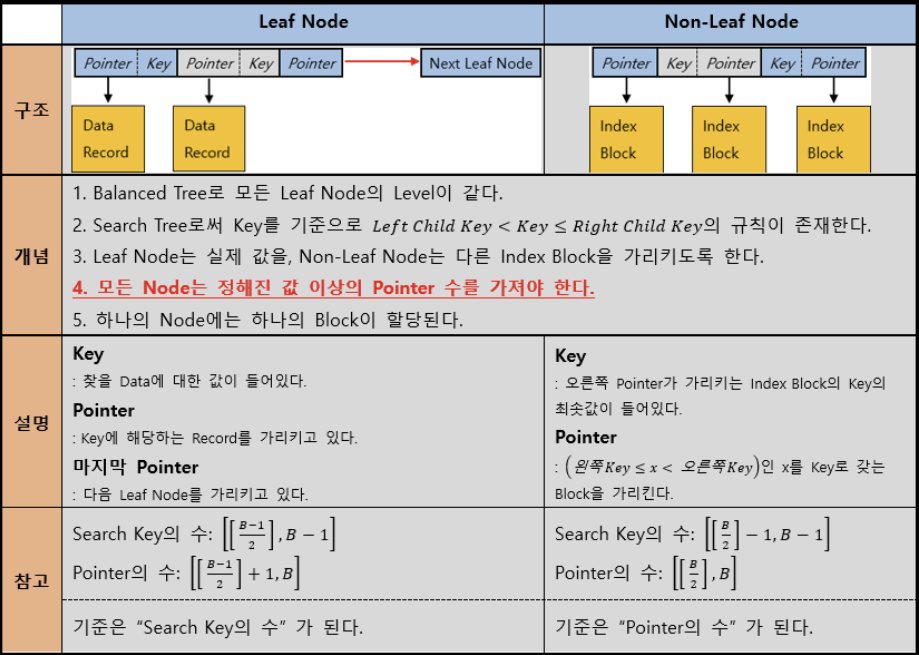
(B는 한 Node(Block)에 들어갈 수 있는 Pointer의 최대 개수를 의미한다.)
(Root Node에 대해서는 Pointer 수에 대한 기준이 $[2, B]$로 예외적으로 존재한다)
Search
- Point Query
- 방법
- Search Tree임을 활용해 Leaf Node까지 이동하면 찾을 수 있다.
- I/O Complexity
- $O(log_B(N))$
($Height+1$번 Block에 접근하게 되기 때문)- Range Query
- 방법
- Point Query를 활용해 최솟값을 찾아 data를 Return하고,
Leaf Node를 쭉 훑으면서 최대값이 나오기 전까지 Data를 Return한다.
- I/O Complexity
- $O(log_B(N))+\frac{T}{B}$
($Height+1+\frac{T}{B}$번 Block에 접근하게 되기 때문)(T는 찾고자하는 Record의 개수)
Update
Leaf Node에 Insertion/Deletion을 수행하고 이것이 Propagate될 경우,
Non Leaf Node에서의 Insertion/Deletion을 수행한다.Root가 Split되는 경우는 Height가 증가할 때 뿐이다.(역도 성립)
OverFlow와 UnderFlow는 Parent로 Propagate될 수 있다.
참고
B+ Tree는 Update에 Cost가 발생한다는 단점이 있었다.
이때, Primary Index는 어쩔 수 없지만 B+Tree로 구현된 Secondary Index는
Data자체가 아닌 Primary Index를 Indexing하므로써, Update의 Cost를 없앨 수 있다.
.png)
.png)
Multi Key Access
여러 Index File을 활용해야 하는 경우 다음과 같은 방법을 사용할 수 있다.
먼저 하나의 Index File로 Data를 검색한다. 그리고 그 결과에 대해 나머지 조건을 Sequential하게 검사한다.
각각의 Index File로 Data를 검색한다. 그리고 그 결과의 교집합을 구한다.
Index File의 Dememsion을 늘려 다시 만든다. (학부생 수준 X)
MySQL
- STUDENT Table에 대해서
${name, sex, dno}$를 index로 하는 BTREE Index File생성1 2
CREATE INDEX student_index ON STUDENT(name, sex) USING BTREE;
- STUDENT Table을 대상으로 생성한 Index File분석
1
SHOW INDEX FROM STUDENT
|Table|Non_unique|Key_name|Seq_in_index|Column_name|Collation|Cardinality|…| |—–|———-|——–|————|———–|———|———–|—| |student|1|student_index|1|name|A|1030|…| |student|1|student_index|2|sex|A|2038|…|
- Table: table 이름
- Non_unique: 인덱스의 중복값 가능 여부(1→가능, 0→불가능)
- Key_name: 인덱스의 이름
- Seq_in_index: Multi Column Index일 경우 필드의 순서
- Column_name: 해당 Column의 이름
- Collation: 인덱스 정렬 방식(A→오름차순, D→내림차순)
- Cardinality: 해당 컬럼의 상대적인 중복도 수치
- Cardinality낮음 → 중복도 높음
- Cardinality높음 → 중복도 낮음
Cardinality가 높은 Column에서 낮은 Column순서대로 Index를 생성하는 것이 효율적임
- Query 실행 계획
1
Explain + (SQL Query)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | NULL | ref | student_index | student_index | 203 | const | 24278 | 10.00 | Using index condition |
- rows: 쿼리 전체에 의해 접근하는 행의 수
- filtered: 필터링 되고 남은 레코드의 비율(0~100)
(Join이나 Where절에서 얼마나 많은 행이 필터링 되었는지 알 수 있음)