4. Attention
Attention
1. BackGround
1) Concept
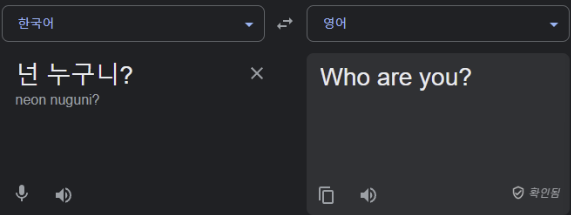
RNN모델들은 Sequential Data를 Fixed Data로 바꾸는 모델이었다.
이번 장에서는 Sequential Data를 다른 Sequential Data로 변형해 주는 방법을 알아보자
이 때, 가장 큰 문제는 입력의 길이와 출력의 길이가 다르기 때문에 일반적인 RNN 모델들을 바로 사용할 수 없다는 것이다.
예를 들어 RNN을 사용하면 “넌 누구니?” 와 같이 2개의 입력이 들어갈 경우 “Who are you?” 와 같은 길이가 3인 출력이 나올 수 없다.
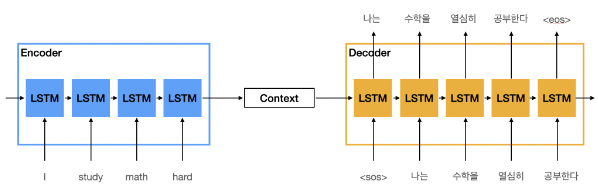
Encoder & Decoder
기존의 LSTM이나 RNN으로는 입력과 출력의 길이가 같은 문장밖에 처리할 수 없다.
입출력 문장의 길이가 다를때 활용할 수 있는 대표적인 방법은 Encoder와 Decoder를 사용하는 것이다.
Encoder는 입력할 Sequential Data를 하나의 정보로 압축하고,
Decoder를 통해 이 정보를 사용해 다시 Sequential Data를 만들어내게 된다.

2. Basic Model
1) Seq2Seq
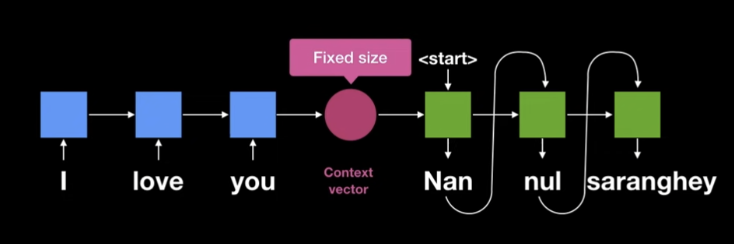
Fixed Size Context Vector
Seq2Seq에서는 RNN기반의 Encoder를 통해 하나의 고정된 크기의 Context Vector를 생성한다.
Context Vector는 Start Token과 함께 Decoder에 들어가 단어를 하나 생성한다.
이후부터는 생성된 단어를 다시 Decoder에 넣는 과정을 End Token이 나올때 까지 반복한다.
- 단점
- 고정된 Size의 Context Vector를 사용하기 때문에 입력 문장의 길이가 길어질 경우, Vector가 이 정보를 표현할 수 없어 성능이 매우 떨어진다.
Encoder Decoder
Encoder와 Decoder로 Vanila RNN을 사용할 경우
Exploding/Vanishing Gradient에 빠질 가능성이 크다.따라서 보통 LSTM을 가지고 Encoder와 Decoder를 만든다.
Trick
간단한 트릭이긴 하지만, 입력 데이터의 첫 글자는 뒤로 갈수록 변형되기 때문에,
Decoder에 처음으로 입력될 때, 이 첫 글자의 정보가 제대로 입력되지 않을 가능성이 있다.위의 정보가 정확한 근거는 아니겠지만 실제로 입력 데이터를 반전시킬 경우 성능 향상이 있다고 한다.
2) Seq2Seq + Attention
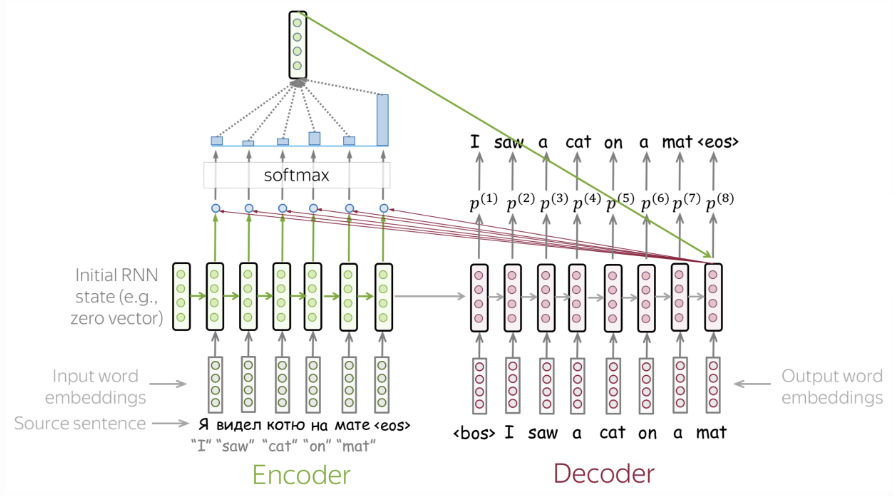
Purpose
Seq2Seq은 고정된 크기의 ContextVector를 사용해 모든 정보를 압축하여 정보의 손실(Bottleneck)이 발생한다.
$\rightarrow$ Non-Fixed size Context VectorRNN의 고전적인 문제인 Vanishing Gradient문제가 여전히 존재한다.
$\rightarrow$ Attention
(이 외에도 각각의 State에 가중치를 사용해 State별로 중요한 단어들을 학습할 수 있다는 장점등이 있다.)동작과정
1. Initiate Decoder State
먼저 RNN을 반복하여 통과시켜
Initial Decoder State를 만든다.2. Attention Score
이 Decoder State(1개)와
각 단계의 Encoder State(n개)로
각각 Attention연산을 수행한다.
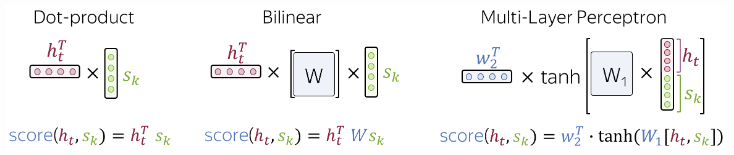
Attention시 사용할 수 있는 방법은 다음과 같다.
- Dot-Product Attention
- Bilinear Attention
- Multi-Layer Perceptron Attetion3. Softmax
Attention 결과에 Softmax를 씌워 확률로 만든다.
이를 통해, Decoder에서는 현재 어떤 단어에
얼마나 집중해야 할 지 알 수 있다.4. Attention Value(Context Vector)
입력 단어들을 통해 생성됐던 Hidden State에 대해
Softmax를 통과한 Attention Score와
가중합(Weighted Sum)한다.5. Decoder
ⅰ) Attention Value의 결과를 반영하기 위해
기존의 Decoder State와 Concatenate한다.
ⅱ) Concatenate된 신경망은 다시 신경망을 거쳐
기존의 Decoder State와 크기를 맞춰준다.
ⅲ) 마지막으로 이 State와 Token을 사용해
다음에 나올 단어를 예측한다.Teacher Forcing
Seq2Seq에서는 Decoder의 결과(출력된 값)을 다시 다음 Decoder의 Token으로 사용한다.
이때, 학습이 되기 전에는 Prediction을 수행하면 우리가 원하지 않을 결가 나온다는 것이 자명하다.즉, 다음 Token부터는 엉뚱한 값을 넣게 된다.
이를 방지하기 위해 학습시에는 예측 값을 Token으로 사용하는 것이 아닌, 정답값을 따로 넣어 Token으로 사용한다.
단점
Attention을 활용해 많은 장점을 갖게 되었지만 결국 RNN을 활용해 학습 시켜야 한다.
즉, 입력을 Sequential하게 입력해 학습시켜야 하기 때문에 학습 시간이 오래 걸리고, 입력의 길이가 길어지는데에도 한계가 존재한다.
.png)
.png)
.png)
.png)
.png)
3) Show, Attend, and Tell
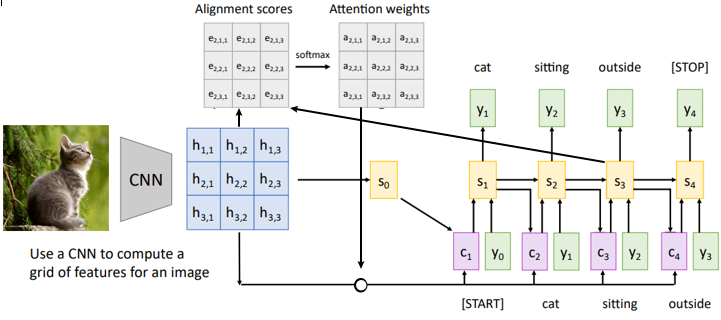
Purpose
- 이전 논문인 Show and Tell에서는 기존의 seq2seq과 비슷한 문제들을 갖고 있었다.
(항상 같은 Context Vector를 참고하여 캡셔닝하는문제)
$\rightarrow$ Attention동작과정
1. Initial Decoder State
ⅰ) CNN으로 Feature Map을 뽑아낸다.
ⅱ) Feature Map을 Grid로 나눈다.
ⅲ) Global Average Pooling을 통해 Decoder State를 만든다.2. Alignment Score(($\approx$ Attention Score)
Seq2Seq와 마찬가지로 Attention을 통해
$s_0$와 $h_{i, j}$간의 유사도 점수를 구해준다.3. Context Vector
Seq2Seq와 마찬가지로 Softmax를 통해
Alignment Weights를 구하고 기존의 Feature Map($h_{i, j}$)와
Weighted Sum을 통해 Context Vector를 구한다.4. Predict
ⅰ) 기존의 Decoder State $s_0$와 Context Vector를 합친다.
ⅱ) Start Token인 $y_0$를 사용해 Decoder에서
Prediction을 수행한다.5. 반복
위의 과정을 반복 수행하며 문장을 만들어 나간다.Alignment Weight 시각화
.png)
.png)
.png)

3. Attention Layer
위의 Basic Model과 같이 Attention Model이 주목받기 시작하자, 이 후부터는 이 Attention과정을 CNN과 같은 하나의 Layer로 취급하여 모델을 설계하기 시작한다.
| Attention Layer | Show, Attend and tell | |
|---|---|---|
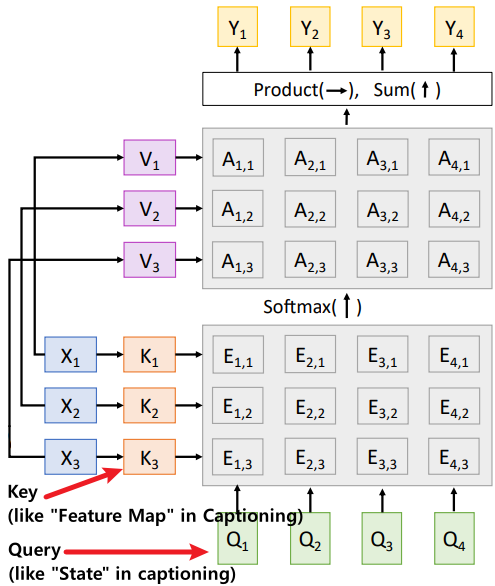 | .png) | |
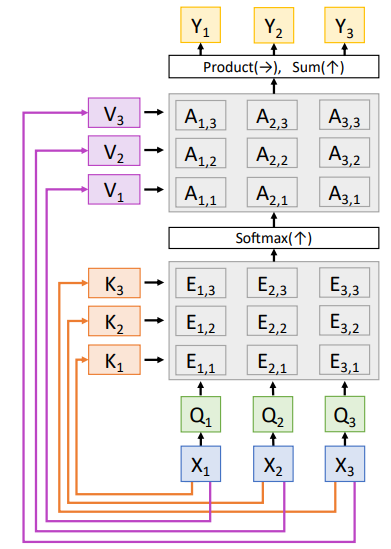
| Query (알고싶은 대상) | $Query = \mathbf{W}_q \mathbf{x}$ | $s_0$ |
| Key (비교할 대상) | \(Key = \mathbf{W}_k \mathbf{x}\) (InputVector $X$에 MLP를 적용해 생성) | {$h_{i, j}$} |
| Context Vector 생성 도구 | \(Value = \mathbf{W}_v \mathbf{x}\) (InputVector $X$에 MLP를 적용해 생성) | {$h_{i, j}$} |
| Output (Context Vector) | $Y=AV = \text{softmax}(\frac{\mathbf{QK^T}}{\sqrt{d}})\mathbf{V}$ (Weighted Sum) | $C=AH$ (Weighted Sum) |
| Similarity함수 | Scaled Dot-Product $E=\frac{QK^T}{\sqrt{D_Q}}$ (Q, K의 길이가 클수록 Softmax에 의해 0에 가까운 Gradient가 많이 발생한다.) (Gradient Vanishing현상) | - Dot-Product Attention($E=QK^T$) - Bilinear Attention - Multi-Layer Perceptron Attetion |
(Attention Layer는 총 2개의 Learnable Parameter를 갖는다.)
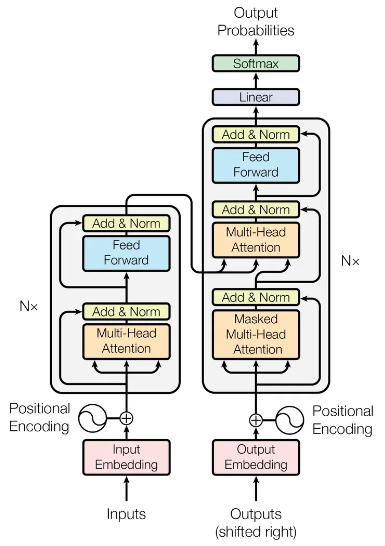
1) Transformer
2017년도에 Attention is All You Need라는 제목으로 발표된 논문에서는 RNN Cell을 아예 제거하고,
오직 위의 Attention Layer만을 사용해 학습시키는 Transformer구조가 제시된다(Attention is All you Need라니… YOLO와 더불어 자극적인 논문 제목 중 하나인 것 같다.)
Purpose(Self Attention Layer)
- Attention Layer의 체계적인 Design
$\rightarrow$ Self Attention Layer
Layer 특징 Self Attention 1. Query를 별도로 입력해주는 것이 아닌
InputVector$X$로부터 MLP를 적용해 생성한다.
$\Rightarrow$ 3개의 Learnable Layer
2. 벡터들의 집합으로서 동작한다.
$if (X_1, X_2, X_3 \rightarrow X_3, X_1, X_2)$
$\Rightarrow (Y_1, Y_2, Y_3 \rightarrow Y_3, Y_1, Y_2)$
$\therefore$ InputVector의 순서정보를 알지 못한다.
$\Rightarrow$ Positional Encoding이 필요하다.
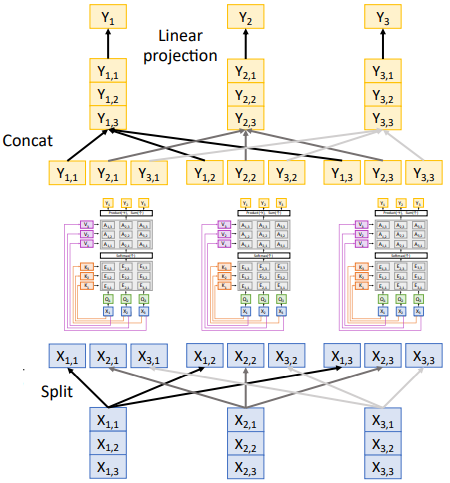
(concat)
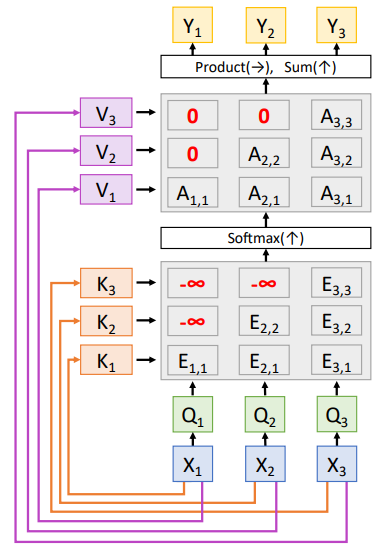
Masked
Self Attention기존의 Encoder Decoder 구조의 모델들은
입력값을 순차적으로 전달받아 $t+1$시점의
예측을 위해 $t$까지의 데이터만 쓸 수 있었다.
하지만 Transformer는 한번에 모든 입력을
받기 때문에 과거 시점의 입력을 예측할 때
미래시점의 입력도 참고할 수 있다.
이를 방지하기 위해 사용하는 것이
Look a Head Mask이다.Multi-Head
Self Attentionn개의 Self Attention Layer를
Parallel하게 동작하도록 구성한 Layer이다.
이를 통해 여러 관점에서 정보를 바라볼 수 있게 한다.Transformer
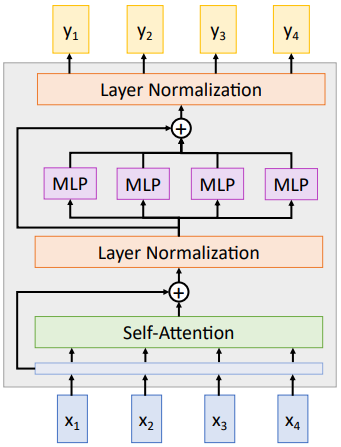
Transformer Block Transformer Architecture 그림 특징 - Layer Normalization - Encoder Decoder Design
- Sequence of Transformer Block
- Positional Embedding
(CNN과 RNN과는 달리 Transformer는
순서정보를 활용하지 않는다.
이를 위해 Positional Embedding을 사용한다.)
2) VIT(Vision Transformer)
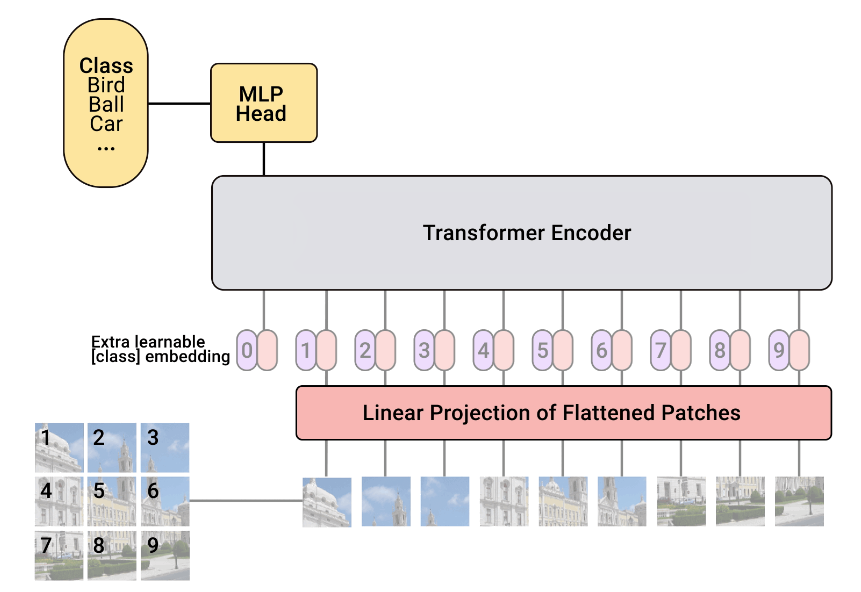
Purpose
- Attention Module을 Image에도 적용시켜보고자 함
ⅰ) 방법1: CNN Architecture사이에 Self-Attention Layer를 넣는다
$\rightarrow$ 그래도 CNN인건 변하지 않는다.
ⅱ) 방법2: Pixel의 관계를 계산할 때 Convolution대신 Self-Attention을 넣는다
$\rightarrow$ 구현이 힘들고 성능도 별로…
ⅲ) 방법3: image를 Resize $\rightarrow$ flatten 하고 각 Pixel에 대해 Self-Attention을 한다
$\rightarrow$ resize결과가 $R \times R$일경우 Self Attention에서 $R^2 \times R^2$ 의 메모리가 필요하다.
ⅳ) 방법4: Image를 Patch별로 나눈 후 linear projection하고 이 Vector들 끼리 Self-Attention을 한다
$\rightarrow$ Vision Transformer동작과정
1. Linear Projection
MLP나 CNN을 사용해 각 Patch들을 $D$차원 Vector로 Flatten한다.
(각 패치의 크기가 $16 \times 16 \times 3$일 때,
mlp weight의 경우 $16 \times 16 \times 3 \times D$의 크기를 갖는다)2. Positional Embedding
각 Patch에 Positional Embedding을 적용한다.
이 Embedding Vector들은 독립적으로 학습된다.3. Transformer
Transformer를 통해 Patch들을 가공한다.
- 이때, 당시 nlp에서 Convention이던 Classification Token을 추가
- 대응하는 Output은 전체 Feature를 표현하는 Global Vector
.png)
.png)
.png)
3) Swin Transformer
Purpose
ViT는 CNN에 비해 Inductive Bias가 적어 학습을 위해서 매우 많은 데이터가 필요하다.
$\rightarrow$ Hierarchical한 구조로 바꿈ViT는 Isotropic한 Architecture이고, Self-Attention특성상 계산복잡도는 이미지의 $(Resolution)^2$에 비례한다.
즉, 고해상도 이미지를 처리하는데 적합하지 않다.
$\rightarrow$ Window Attention
- ※ Inductive Bias
- CNN은 Hierarchical한 구조로 Self-Attention보다 Local한 정보를 처리하는데 적합하다. (Self-Attention은 Global Context를 처리하는데 이점이 있다.)
- 즉, Self-Attention은 조금 더 높은 자유도를 갖고있어 Big Data Set을 처리하는데 유리하지만, Small Data Set으로는 학습에 한계가 있다.
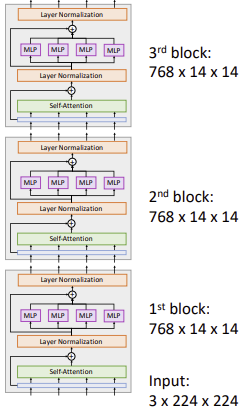
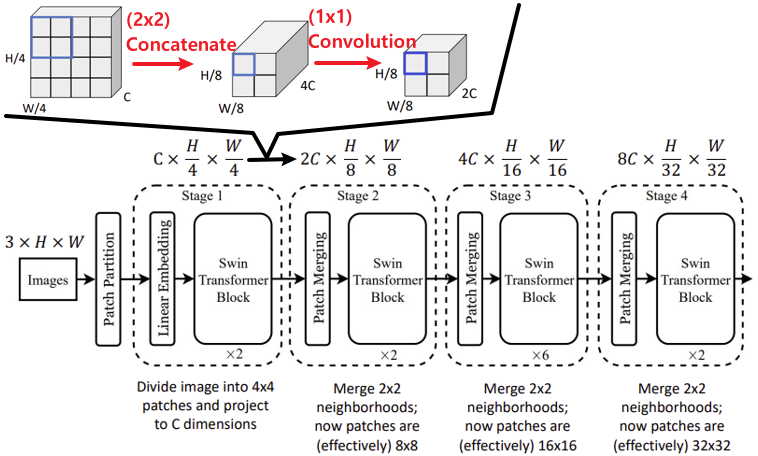
Hierarchical Architecture
ViT Swin Transformer 입력 크기
$=$
출력 크기매 Swin Transformer Block을 지날때마다
Resolution은 줄어들고 Channel은 깊어진다.
- Resolution: Concatenate로 줄임
- Channel: $1 \times 1$ Convolution으로 너무 깊지 않게 유지함Shifted Window Attention
위의 Hierarchical Architecture로 인해 뒷부분의 계산복잡도도 개선되긴 하였지만, 여전히 앞부분의 계산복잡도는 매우 높다.
이를 개선하기 위해 Shifted Window Attention이 도입된다.
Block L Block L+1 1. 기존 Block의 Token Size
$\rightarrow (HW)^2$
2. Window를 적용할 경우 Token Size
$\rightarrow M^2HW$
($=M^4 \times (\frac{H}{M}) \times (\frac{W}{M})$)1. Block L만 사용할 경우
$\rightarrow$ 서로 다른 Window간 정보교환 X
2. Block L+1과 교차하여 사용할 경우
$\rightarrow$ 서로 다른 Window간 정보교환 가능※ Relative Position
또한 이 Window Attention기법 덕분에 Vit에서 사용하는 Positional Encoding을 사용하지 않아도 된다.$Attention(Q, K, V) = SoftMax(\frac{QK^T}{\sqrt{D}}+ bias)V$
대신 Self-Attention을 계산하는 식에서 자신이 속한 Patch에 대해 Patch간의 상대적인 위치인 Relative Position을 입력해준다.
.png)
.png)
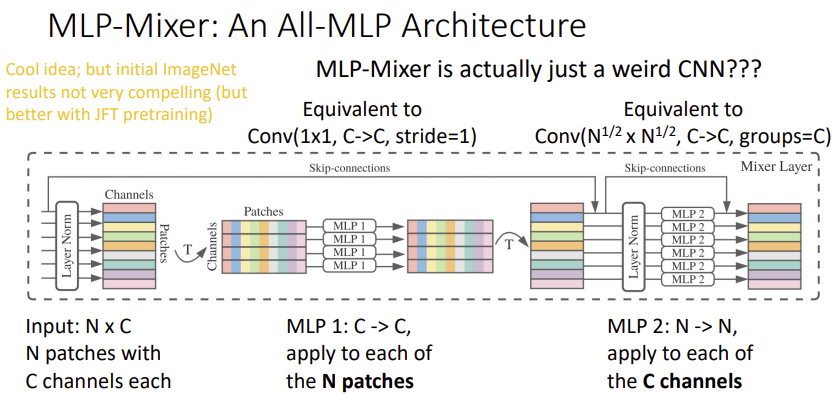
4) MLP Mixer